The future of operations is now
Making on-call life easier in the world that agile created

Remember when each release deserved a party?
When I started my career at Apple back in 2001, we packaged and shipped physical boxes for each release of OS X. As an engineer, this led to a highly bureaucratic process; we had feature freeze, design freeze, code freeze, all leading up to a period of strict change control, where you had to present each change to a panel for approval. This rigid process meant that there was a lot of pressure to hit dates since there were physical discs to print, but it also meant that once we shipped, there was a collective sigh of relief… and a release party. Engineers could truly decompress since the fastest a patch release could be shipped was weeks or months, not minutes or hours.
So when I joined Google and was handed a pager a few months into my job, it took me by surprise. Not only did I not understand that the industry was undergoing a fundamental change, but I was also woefully unprepared for the job. We had Macbooks for our development environment but our production servers were Windows. So the first time I was paged, my first stumbling block was as basic as how to open up a terminal to debug.
Agile and the birth of modern on-call
These days, agile is often synonymous with a modern engineering org. The slogan “move fast and break things,” often associated with agile, is focused on the benefits for engineering, the ability to move with less friction than the traditional operations/IT team model. However, the corollary has often been overlooked: this model necessitates highly skilled engineers who are familiar with the code to operate it.
In the old world of long bake periods, the role of support was to help diagnose and work around user issues. With agile, because deployments are continual, changes are usually small chunks that the team can fix forward or roll back. But despite the best efforts at automated testing, teams are effectively testing their code in production. The implications are that support is just as likely to surface an engineering problem as they are a user error. Support now frequently involves engineering, and the urgency of incidents is now much higher. Agile gave rise to the role of engineering on-call and SRE.
Cracking the code under pressure
Automation seems like an ideal solution, but teams overwhelmingly report that they have little to no automation around incident response. What automation they do have is fragile and creates risk - if the person who wrote the script left the company, what happens when it goes awry? When the product functionality changes, the script needs to be updated. The documentation and knowledge needed to run the script is institutional knowledge that isn’t uniformly shared across the entire team. The philosophy around automation is fundamentally broken; when we think about automation, we need an approach that factors in humans. It’s equally important to consider that some things are better left to human intuition.
The philosophy around automation is fundamentally broken; when we think about automation, we need an approach that factors in humans. It’s equally important to consider that some things are better left to human intuition.
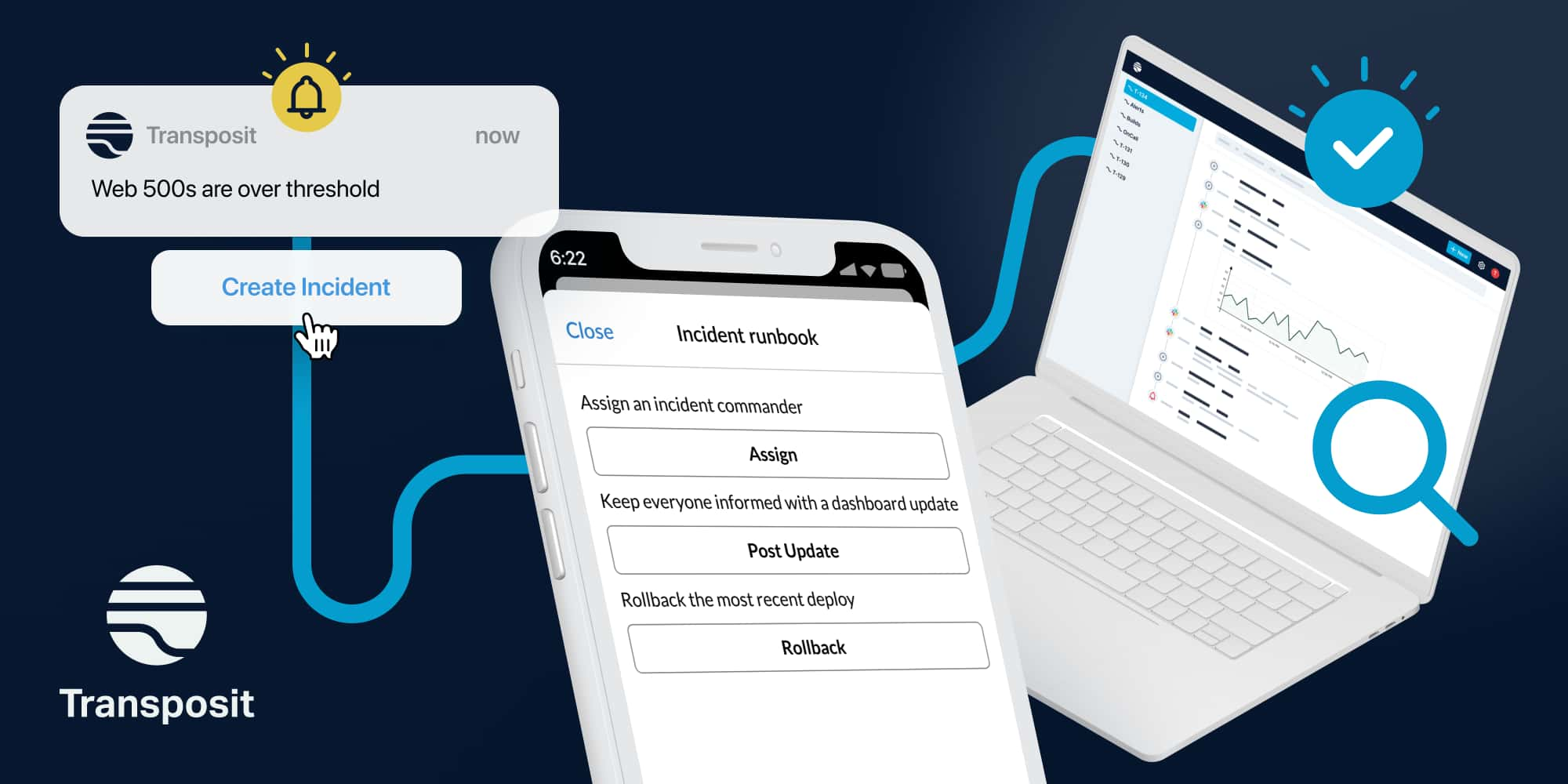
The fast pace of change that agile has brought means that on-call engineers often have to debug code that isn’t theirs. You have on-call engineers having to operate infrastructure when they don’t specialize in ops, and ops having to support application code that they’ve traditionally been able to treat as a black box. Luckily, automation is just one tool at our disposal. What we really want isn’t exclusively automation, it’s codified processes. Codified machine process is automation, but a codified human process is a runbook. The ideal world is about being able to seamlessly bind these two together. When you allow humans to stitch together pieces of automation, you actually end up with more automation and more robust automation. That’s because you can let human intuition step in where the logic to automate would end up being so complex as to cause more problems than it solves, where the logic would be so closely tied to the specifics of a fast evolving product that it would need to be updated almost as frequently as the product itself.
What we really want isn’t exclusively automation, it’s codified processes. Codified machine process is automation, but a codified human process is a runbook.
But even if you have the ability to seamlessly codify human and machine processes, you can’t ever get to zero incidents. Incidents are a result of forward movement and innovation. As you reduce incidents, you free up time for engineers to do what they are really passionate about: building new technology that furthers the business. Everyone wins. However, this speed of innovation is what fuels new areas of uncertainty, new system interactions that may unfortunately interact in surprising ways and fuel more incidents. We are victims of our own success.
This speed of innovation is what fuels new areas of uncertainty, new system interactions that may unfortunately interact in surprising ways and fuel more incidents. We are victims of our own success.
With so much data, why is incident management not more data driven?
The end goal is to prevent incidents and speed up resolution when they do unfortunately occur. If you look at the current incident life-cycle, a lot of our efforts are focused on post-mortems. But these are still very manual, and the data we collect in those post-mortems is often used for accountability and rarely accessible in a usable fashion during an incident. The data is at best used for planning by identifying areas of the system we can fix, runbooks that are missing, and additional areas we can automate. But this process is also very manual; Jira tickets get filed which may or may not be completed.
Why is incident management, which is so closely aligned with engineering, not more data driven? Because so much of the processes are human processes. As an industry, we’ve made huge strides in collecting data through observability tools, but we have almost no data on the human process that binds them together. We need to learn from the innovations in other verticals such as the consumer world where we build user centric tooling that is instrumented to capture semi-structured data around user events. Design tooling that on-call engineers use because they improve their lives, yet helps us answer questions that we can use to improve our incident management – What runbooks are people using? What graphs are pulled and shared? What actions do engineers take on certain alerts?
We all know that there’s also a shortage of SREs, so it’s important that we are able to be strategic around where they should spend their time. I talked to one head of SRE who supports a number of products across their organization. But he observed that he would find their SREs spending time automating a service where the automation had a massive impact on that service’s uptime, only to realize that the service itself had very little impact on the actual business. To be truly strategic, it’s important that we are able to pull together the data across the entire spectrum, including human and machine processes, but also linking this with data on the customer and business impact from systems like Zendesk and Salesforce.
The future of operations is now
With the pandemic placing unprecedented pressure on engineering teams for uptime and digital transformation, the challenges that agile has introduced to engineering organizations couldn’t be more acute. That is why I’m so excited about the platform we’re building at Transposit.
Our human-centric approach doesn’t fight against the natural flow of human and machine processes that teams use across all of their daily activities. Instead, by using the Transposit platform, their existing ecosystem is uplifted, including the quality of life of on-call engineers.
While many companies aim to solve technology problems with technology, at Transposit we solve human problems with technology. Today, many on-call engineers still dread the woefully unprepared midnight alert like I did when I was at Google, but with Transposit as their guide, there is a different, brighter future at hand.



