Automated incident management: How to automate the incident lifecycle
Combining both fully automated and human-in-the-loop automated scripts, explore how your team can automate the entire incident lifecycle — from alert to resolution.

At a recent conference, I was chatting with people about how they automate their incident management. Many mentioned communication automation, like paging on-call and Slack bots that set up channels. But investigating and resolving incidents are still time-consuming, manual parts of the incident lifecycle.
Transposit is built to help teams automate the entire incident lifecycle — from alert to resolution. We can use both fully automated and human-in-the-loop automated scripts to do this. While some tasks will be the same for every incident (e.g., creating a Slack channel), many will not. Transposit runbooks guide responders through the incident, providing them with access to documentation and human-in-the-loop automation (or scripts) that they can run anytime based on their judgment.
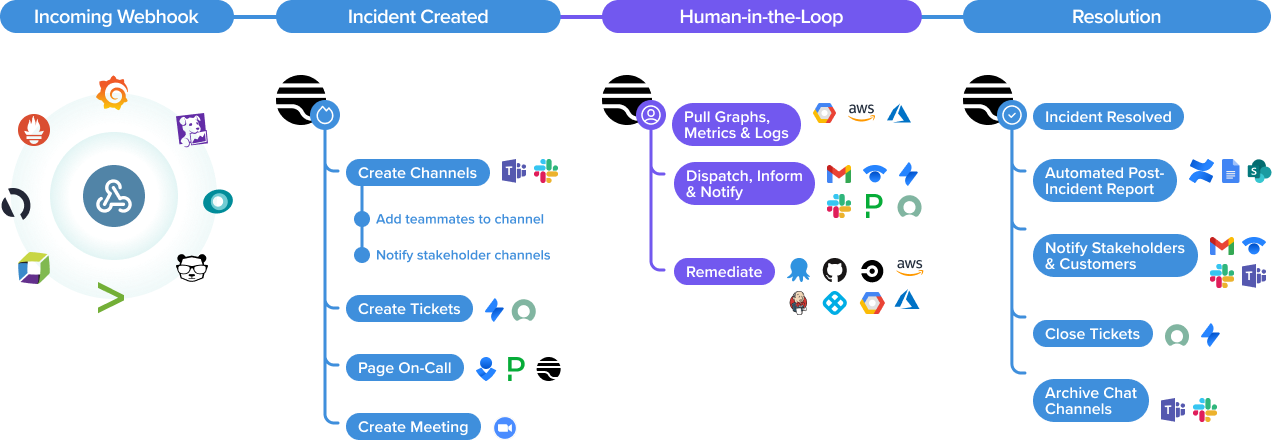
In this article, I’ll explain how Transposit can help you through each phase and drastically reduce incident response and resolution times.
Remember, you can start small and incrementally automate each phase of your lifecycle. The beauty of human-in-the-loop automation is that humans remain in the driver’s seat — you decide if and when to take action and then let automation do the rest.
Incident Intake: reduce the first ten steps to instant
How it works today (estimated time: 15 - 30 minutes):
Once an incident is identified, a responder often enters Confluence or Google Docs to find their incident runbook or playbook. There are a couple of major problems with this method. Firstly, static documentation is prone to being outdated (i.e., team members, tools, processes change). Secondly, while this has written instructions, the responder must manually go between tools to create a Slack channel (and invite teammates), Zoom meeting, and Jira ticket (for instance).
How it works with Transposit (estimated time: 1 minute):
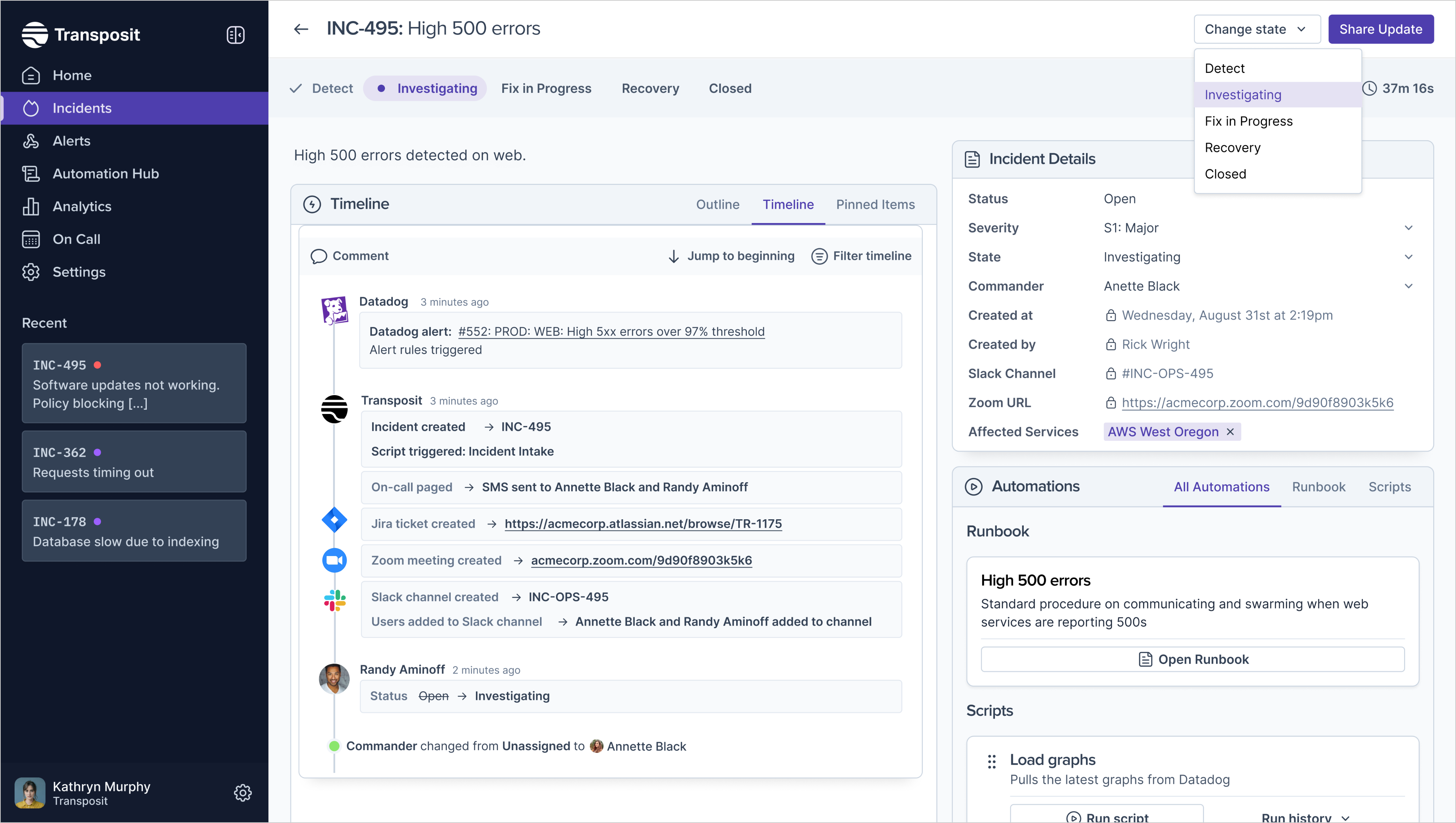
With Transposit, we can fully automate the beginning of an incident. From any alert (e.g. Datadog, PagerDuty, BigPanda), Transposit can automatically create the incident and instantly trigger scripts, including:
- Create Slack or Teams channel and invite teammates
- Create Zoom meeting
- Create Jira, ServiceNow, or Zendesk ticket
Along with the incident being created, responders will have their runbook attached to it, giving them instructions and actions to take.
Engage: page on-call and notify stakeholders, with one click
How it works today (estimated time: 20 minutes):
At this stage, teams may want to dispatch on-call teams and communicate with stakeholders and customers. This often means sending emails, messaging chat channels, and creating a status page incident — all simple but time-consuming tasks. If on-call teams need to be paged, teams also have to create a PagerDuty or Opsgenie incident.
How it works with Transposit (estimated time: 3 min):
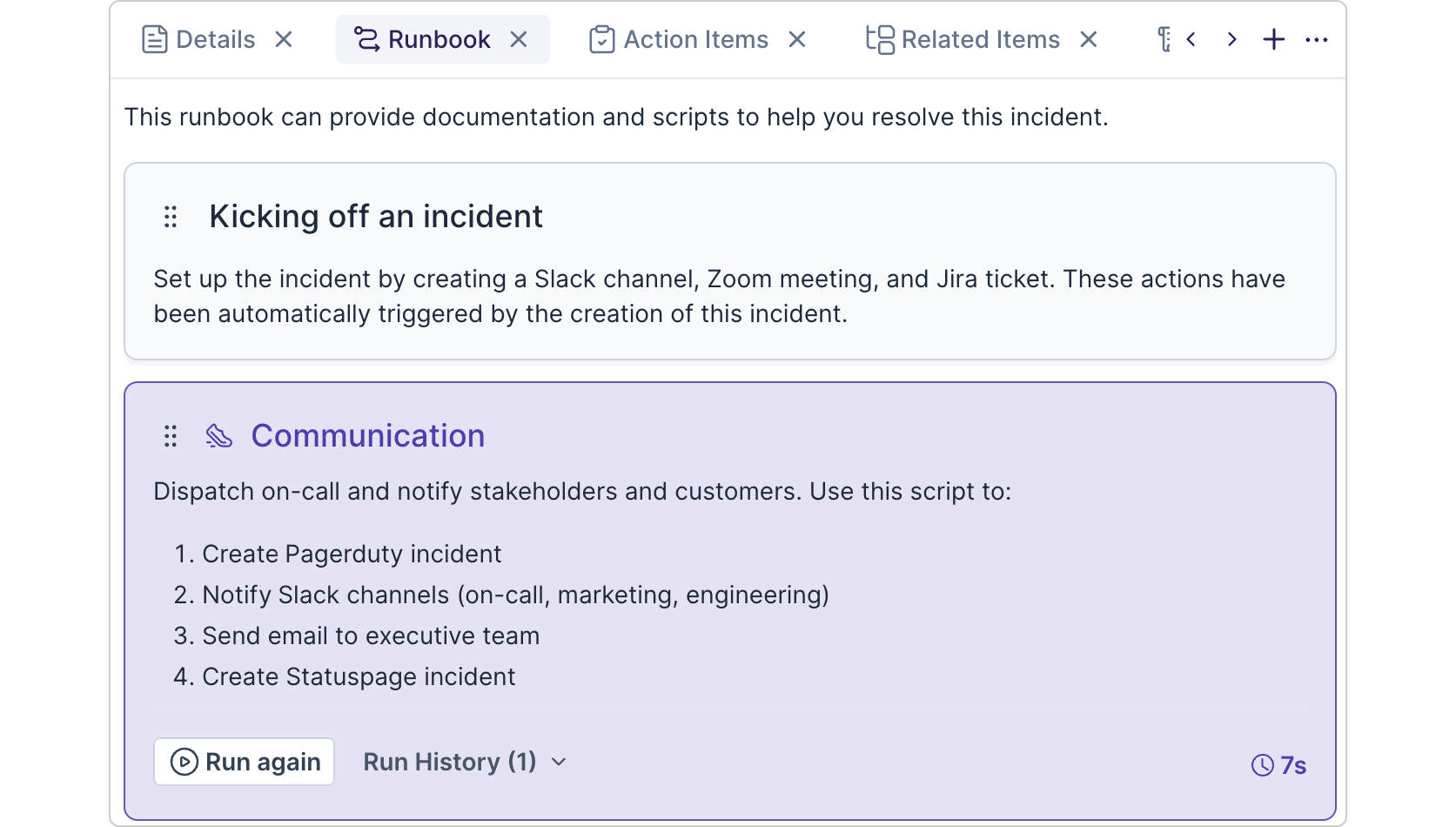
With Transposit automation, we can easily notify both internal and external stakeholders with one script. The script could contain things like:
- Send email to executives
- Message Slack channels
- Create Statuspage incident
- Page on-call through PagerDuty or Opsgenie
Investigate: classify the incident, collaboratively
How it works today:
The data that teams need to understand and determine the customer impact, severity, and the issue is usually spread throughout tools. Teammates are looking at data individually at different times, possibly coming to different conclusions or being unable to share the “why” behind a decision. This data is also not recorded, meaning people joining the incident midway through will not have this context.
How it works with Transposit:
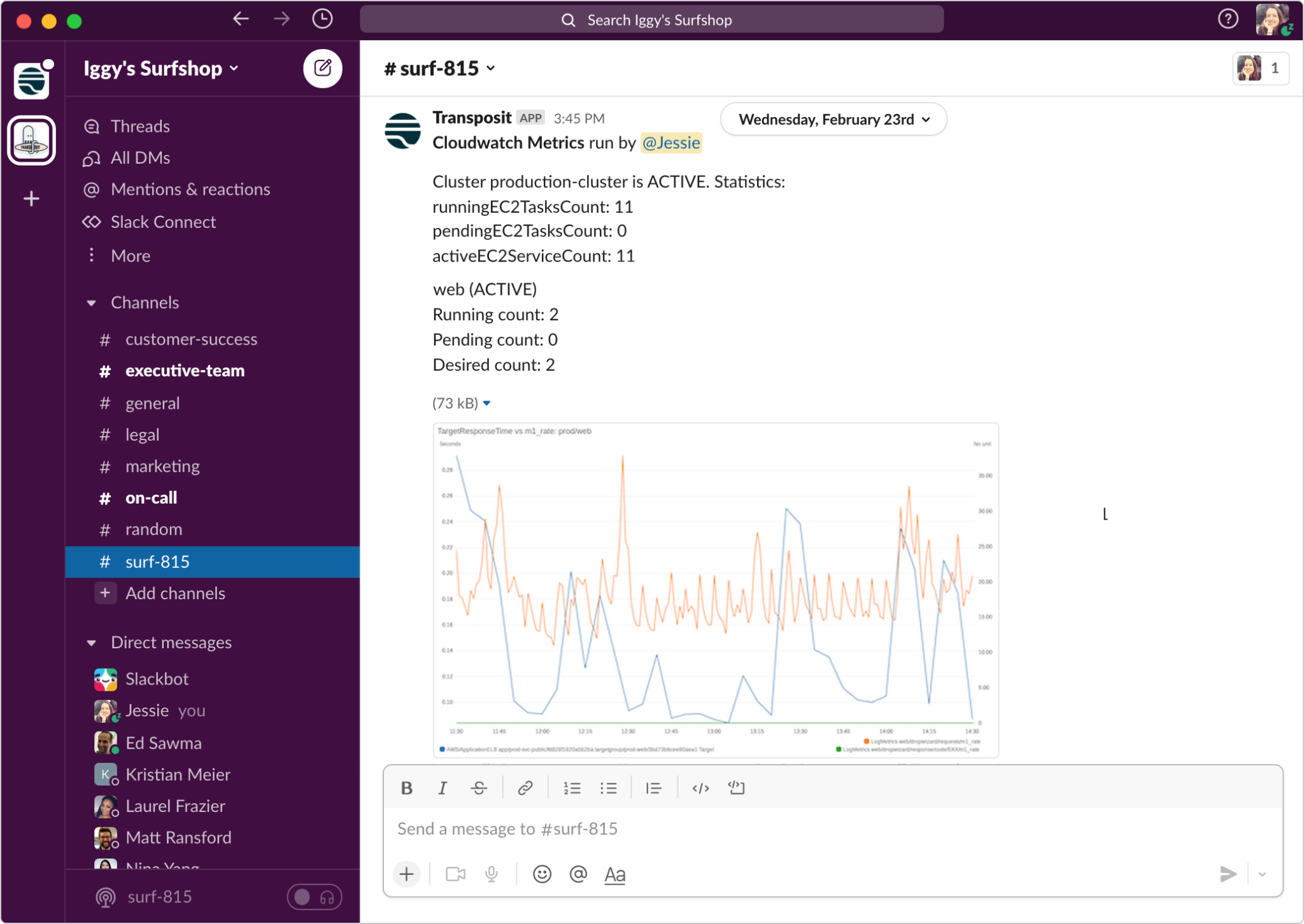
Some parts of this phase can be fully automated, like doing an AWS service status check for every incident. But much of it will be based on the responders’ judgment, so we’ll rely on human-in-the-loop automation. Within an incident, responders have access to runbooks that provide both documentation and scripts to run. This makes it easy for any responder to do things like:
- Pulling metrics, graphs, and logs (e.g., Cloudwatch, Datadog, New Relic, etc.)
- Pulling recent releases (e.g., CircleCI, Jenkins, etc.)
By pulling this data into the incident in Transposit or a Slack channel, we can work collaboratively to investigate. Everything is recorded to the Timeline so it’s clear how decisions were made and ensures stakeholders are kept up to date.
Remediate: mitigate customer impact faster
How it works today:
Apart from being a highly manual and time-consuming phase, responders may not have the institutional knowledge to take action in some tools or services, leading to escalations. People just joining the incident will have to gather all the information from people currently managing the incident, like what actions have been taken, where the relevant tickets and data are, etc.
How it works with Transposit:
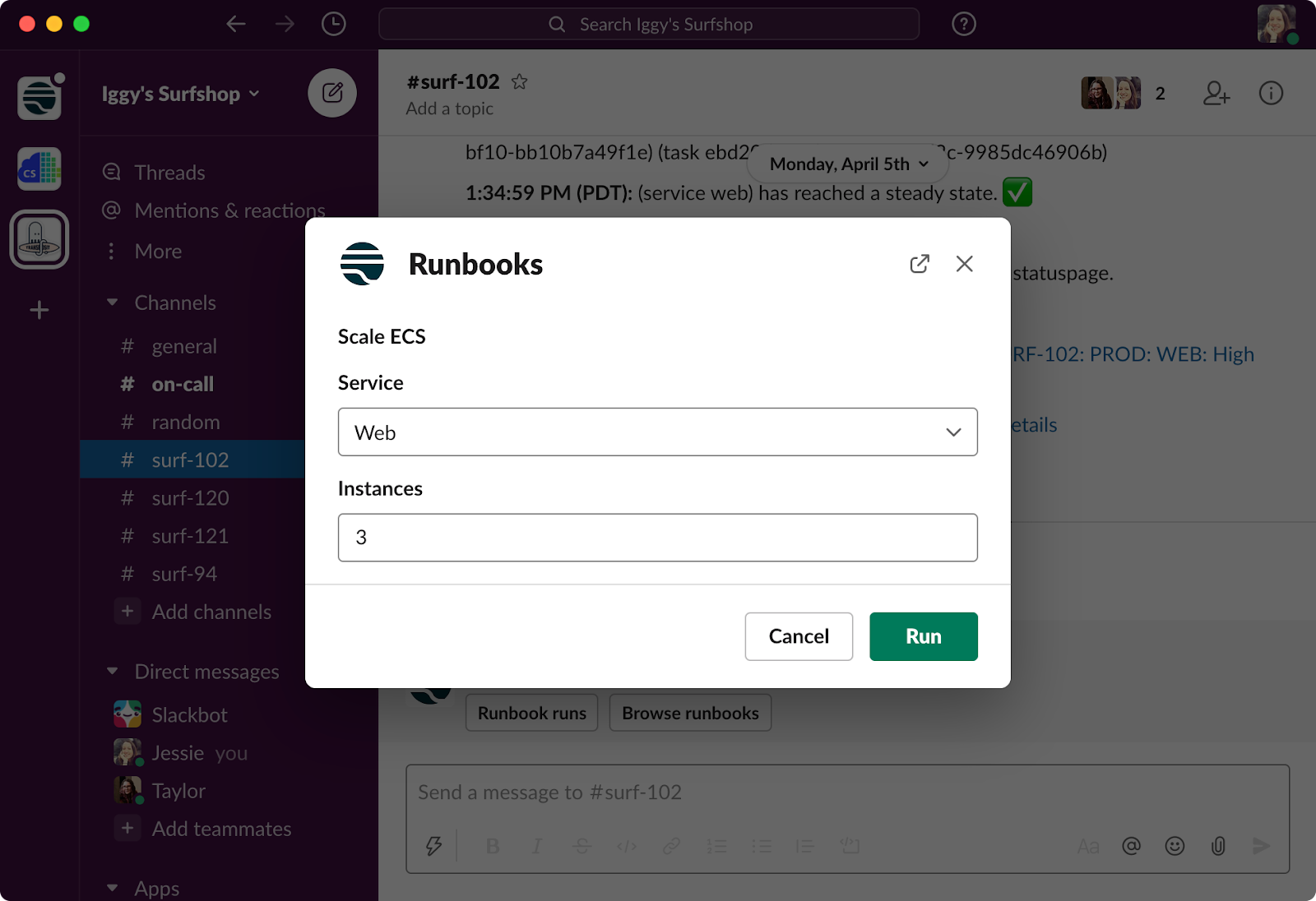
While we can fully automate a lot in the incident lifecycle, remediation usually needs human oversight. However, we can enable humans to take action faster through runbooks, which can have attached scripts like:
- Restart an EC2 instance
- Scale ECS
- Rollback a CircleCI release
For teams that use Slack, running these scripts in a channel using slash commands is easy, giving the entire team visibility into the incident progress. Everything done in Slack will also be recorded in the Timeline.
Teams can sometimes auto-remediate incidents when it is a known and repetitive issue. For example, say a database used internally fails periodically due to a known issue yet to be resolved, thus taking it offline. We can configure alerts to create an incident anytime the database is unresponsive, that then automatically runs automation to restart the server.
Learn: drive change with incident insights
How it works today (estimated time: 2+ hours):
After an incident is resolved, most teams create a post-incident report, often taking two to four hours to revisit tools and chat channels to grab screenshots, copy and paste comments, and record the actions taken. Teams also need to close out tickets and chat channels and notify customers and stakeholders that everything is resolved.
How it works with Transposit (estimated time to close channels, tickets, and create post-incident report: 1 minute)

Transposit Timelines automatically record every action during the incident (including Slack conversations) helping teams learn from past incidents. Even more, we can fully automate closing out the incident and creating a post-incident report with scripts to:
- Create a post-incident report and export it to Google Docs of Confluence
- Close tickets
- Archive chat channel
- Update and close the Statuspage incident
- Notify stakeholder Slack channels
Transposit also provides analytics (MTTR, MTTA, etc.), which helps teams analyze their incident workflows.
Automate your incident management
Transposit helps teams both standardize and automate their incident management. You can start small and incrementally automate your workflows while keeping humans in control.
Want to try it out for yourself? Jump right in with pre-built incident templates and hundreds of integrations. Sign up for free.



