BigPanda + Transposit: Accelerate Incident Response, from Auto-Remediation to Human-in-the-Loop
Use enriched alerts from BigPanda to trigger the relevant automated workflow, either to auto-remediate or bring humans in the loop

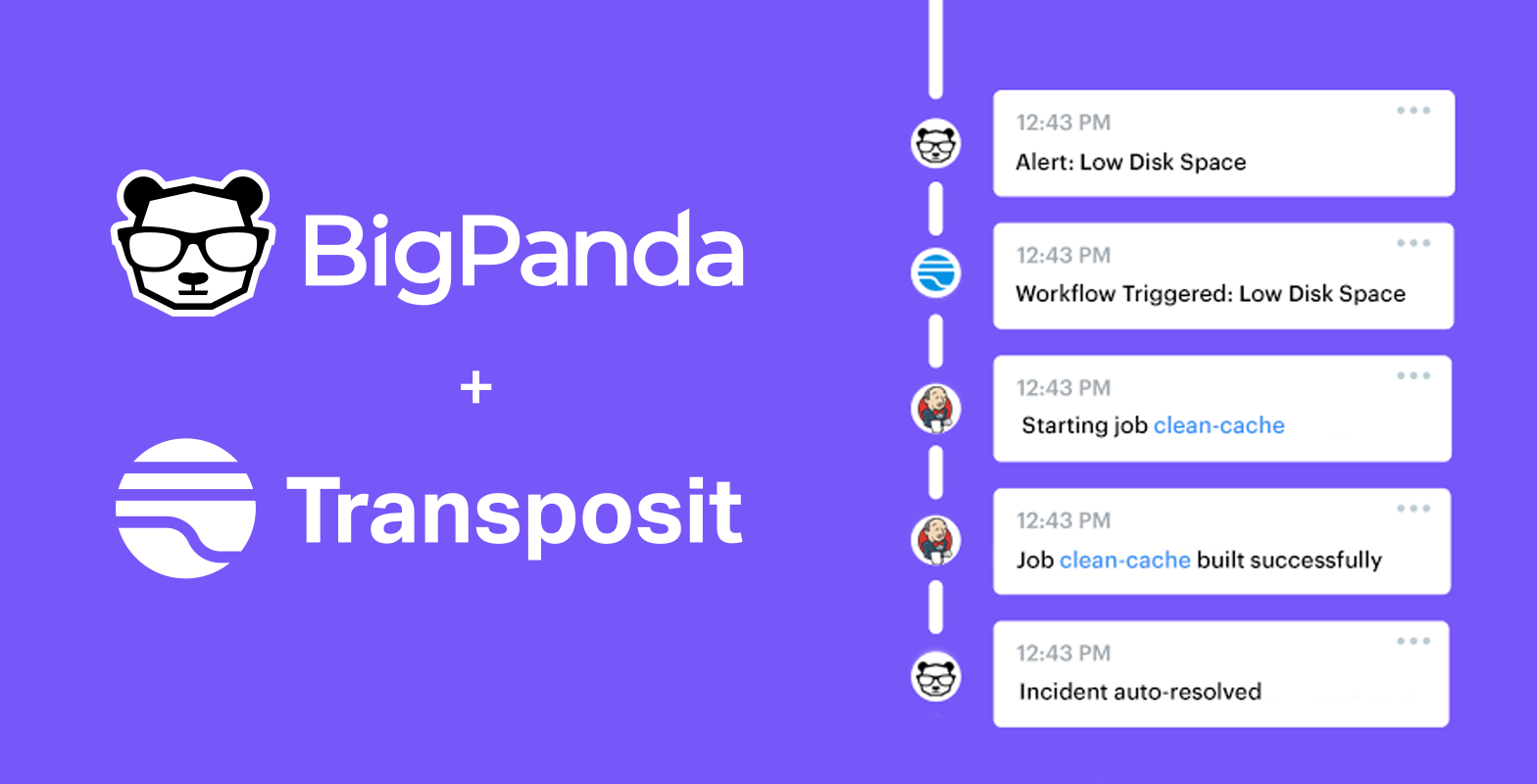
The beauty of automation should be in its simplicity. It can help teams be more efficient, respond to events faster, and reduce unnecessary toil — but all this is trivial if the complexity of automation outstrips the benefits. BigPanda and Transposit in concert create an elegant solution to a common challenge: how to quickly identify, respond to, and remediate incidents. Together, BigPanda and Transposit automate the full lifecycle of an incident and ensure healthy services and great customer experiences.
Using BigPanda’s AIOps platform and Transposit’s process automation platform, teams are now able to respond to incidents faster. Using enriched alerts from BigPanda, Transposit is able to trigger the relevant workflow, whether that’s fully remediating the issue without any human intervention or bringing humans in to use judgment and collaborate.
Here’s how it works…
Auto-remediation workflows
Auto-remediation is a great solution for predictable, known issues. For instance, many operations teams run into the scenario where their server disk space is low. While it’s a known issue that occurs, it can be difficult and resource-intensive to make sure all of your servers will have empty disk space all of the time. This is a great opportunity for auto-remediation.
Using this “low disk space” example, let’s see how BigPanda and Transposit together can auto-remediate the issue.
When an alert comes into BigPanda, the alert can have various attributes, like check: “Low Disk Space”, which allows BigPanda to enrich and add more contextual information to the incident.
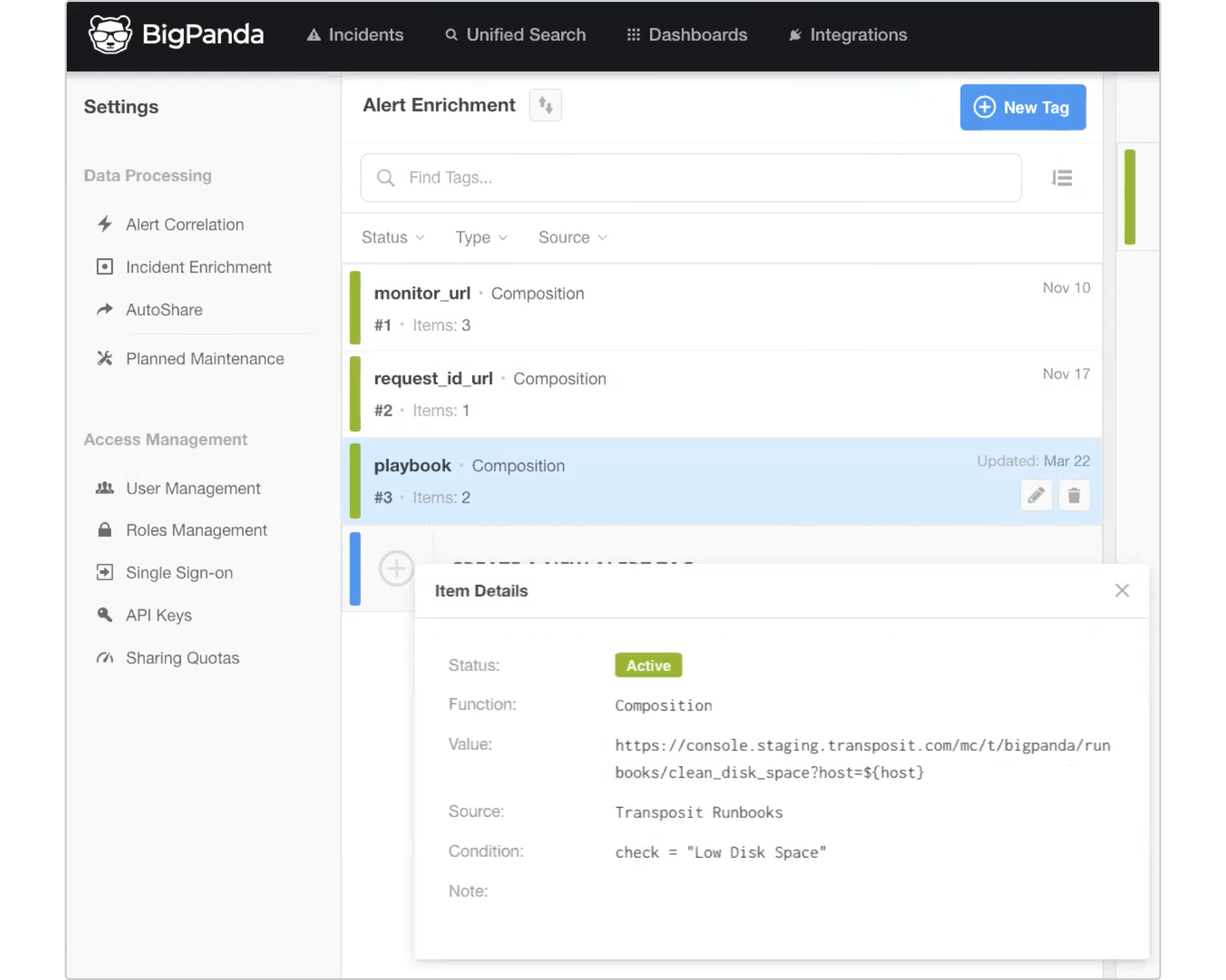
In BigPanda, we’ve created an enrichment property called a Playbook. Using this property, Transposit can kick off the relevant automated workflow. Here we’ve added a condition where check = Low disk space will kick off the Low disk space Transposit automated workflow.
As you can see below, the relevant Transposit workflow has been attached to the BigPanda incident.
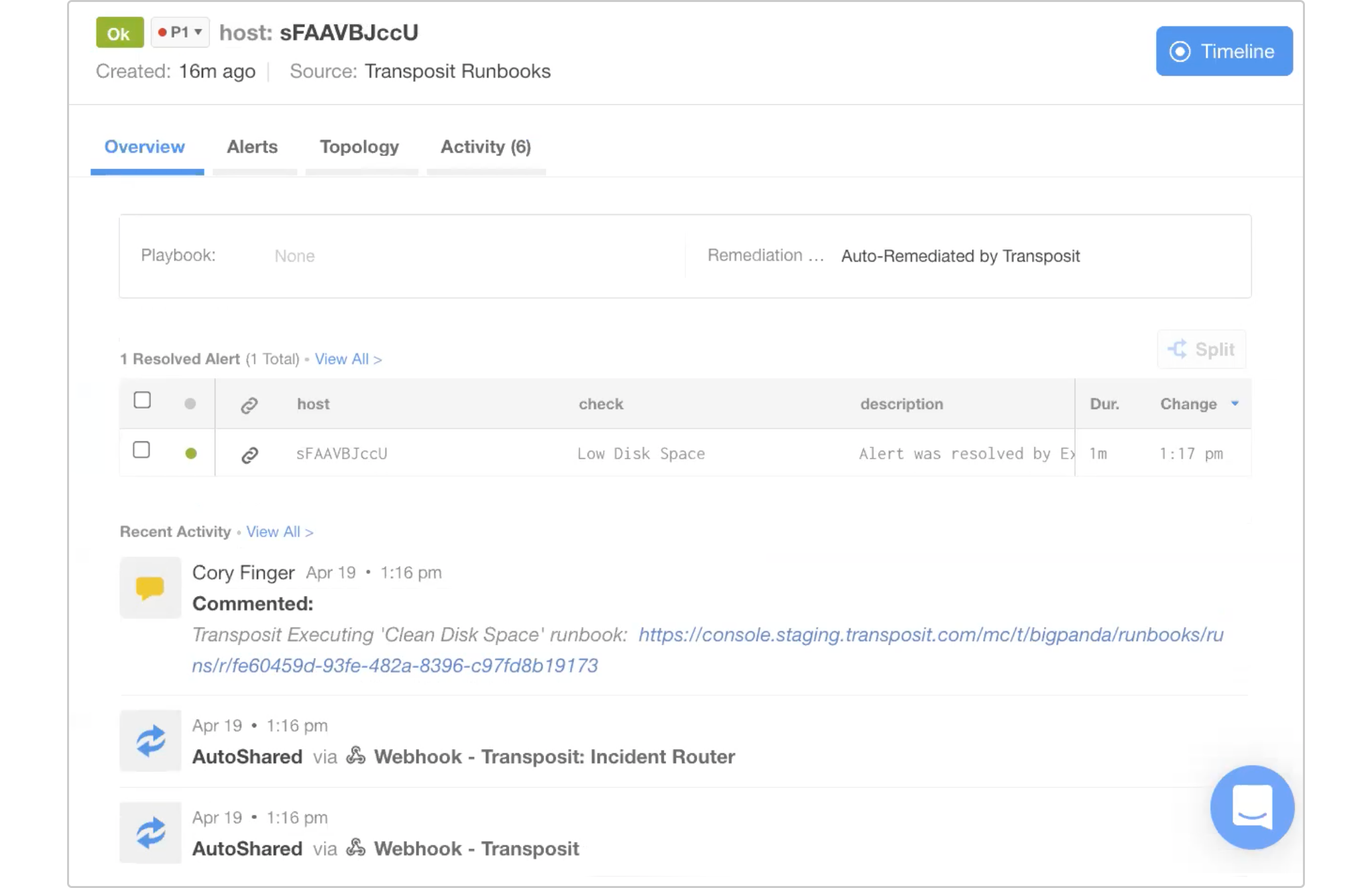
Clicking the link, we can head into Transposit to see the full audit log of everything that took place, including a Jenkins job that cleaned the server and checked that it was online.
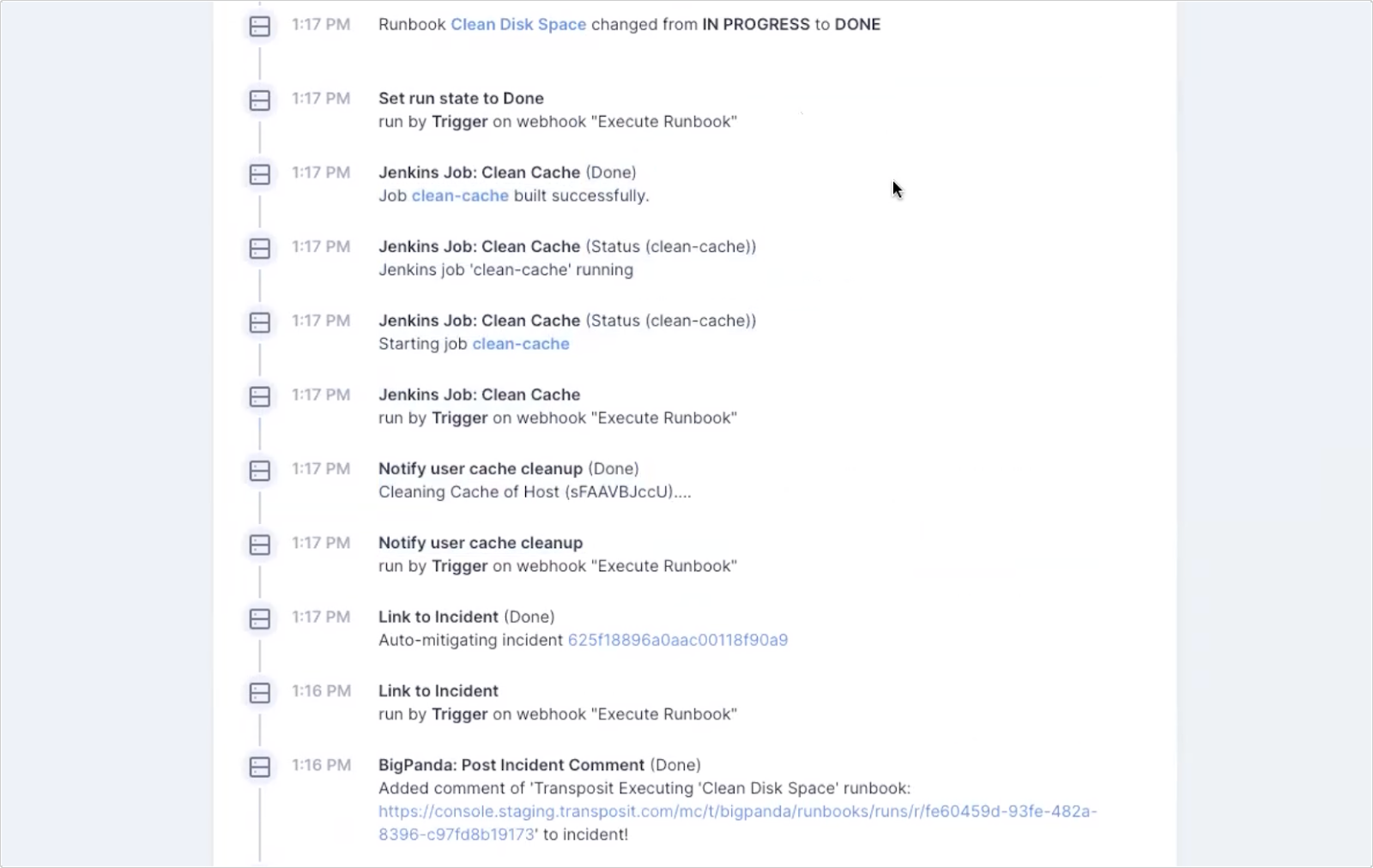
The incident was then auto-resolved, never having to pull in an operator or notify anyone. The workflow will only pull in someone if something goes wrong.
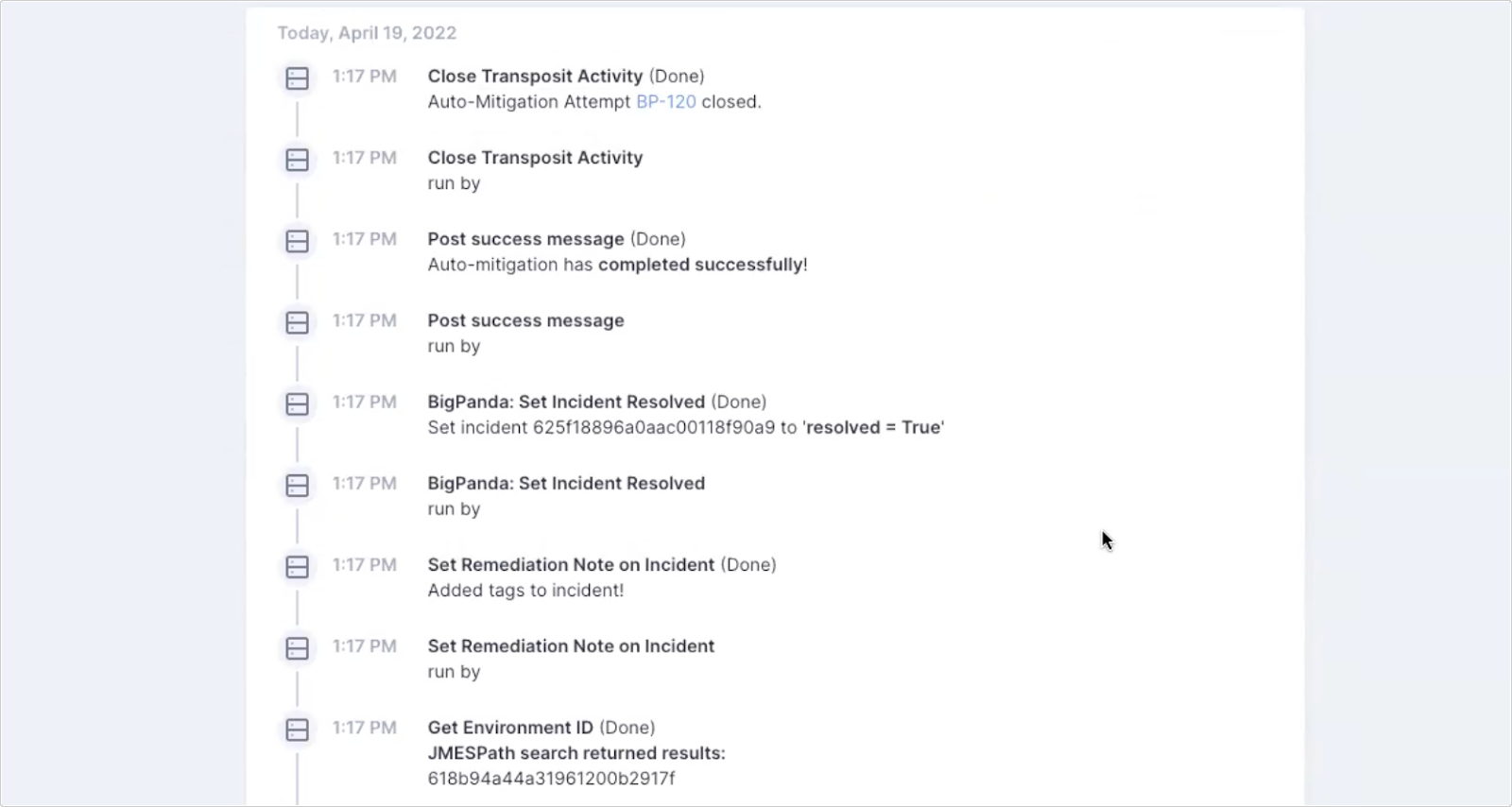
Without any human intervention, the server has been cleaned and is functioning normally.
Human-in-the-Loop automated workflows
While auto-remediation is the goal for many teams, often times we need humans to step in to collaborate, use judgment, and make decisions together.
In this example, we have a “possible outage,” for which we’ll use a human-in-the-loop automated workflow.
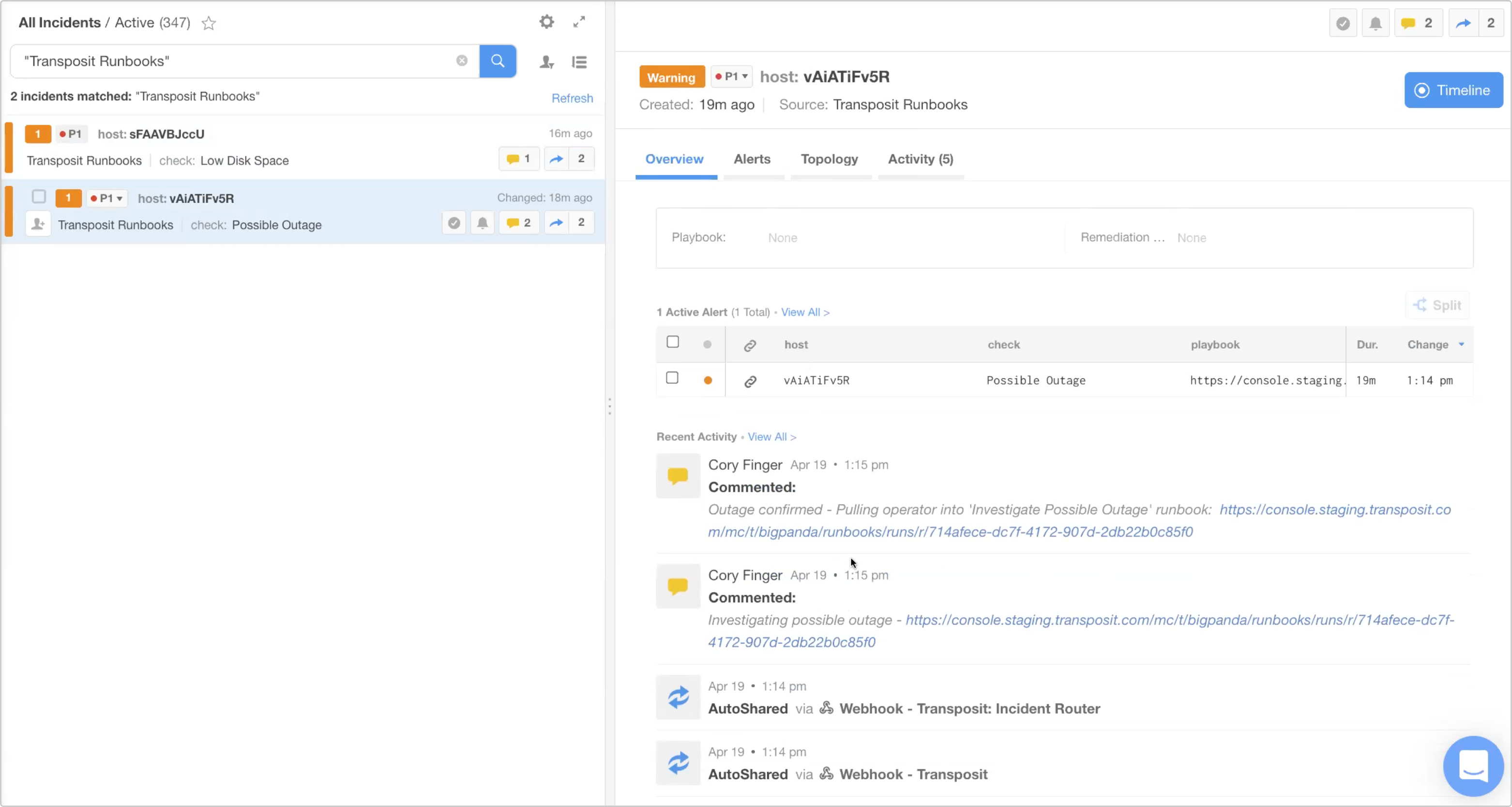
Using the condition check = Possible Outage, a Transposit workflow has been triggered.
Before pulling in an operator, it performed a check against the server. It pinged the URL and saw that it’s returning a 503, verifying that the server is, in fact, down.
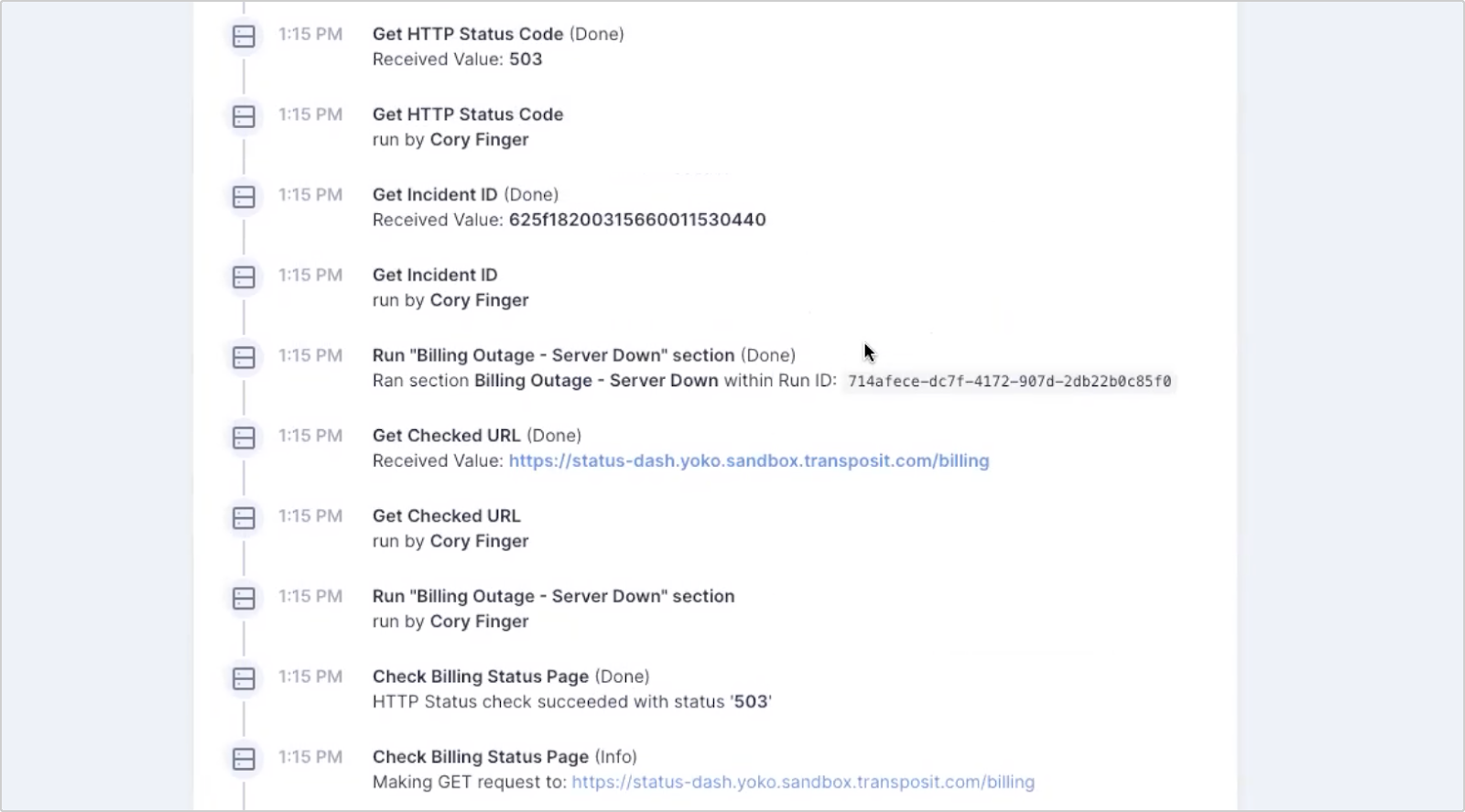
Once verified that there is an outage, it created a Transposit Activity for this outage.
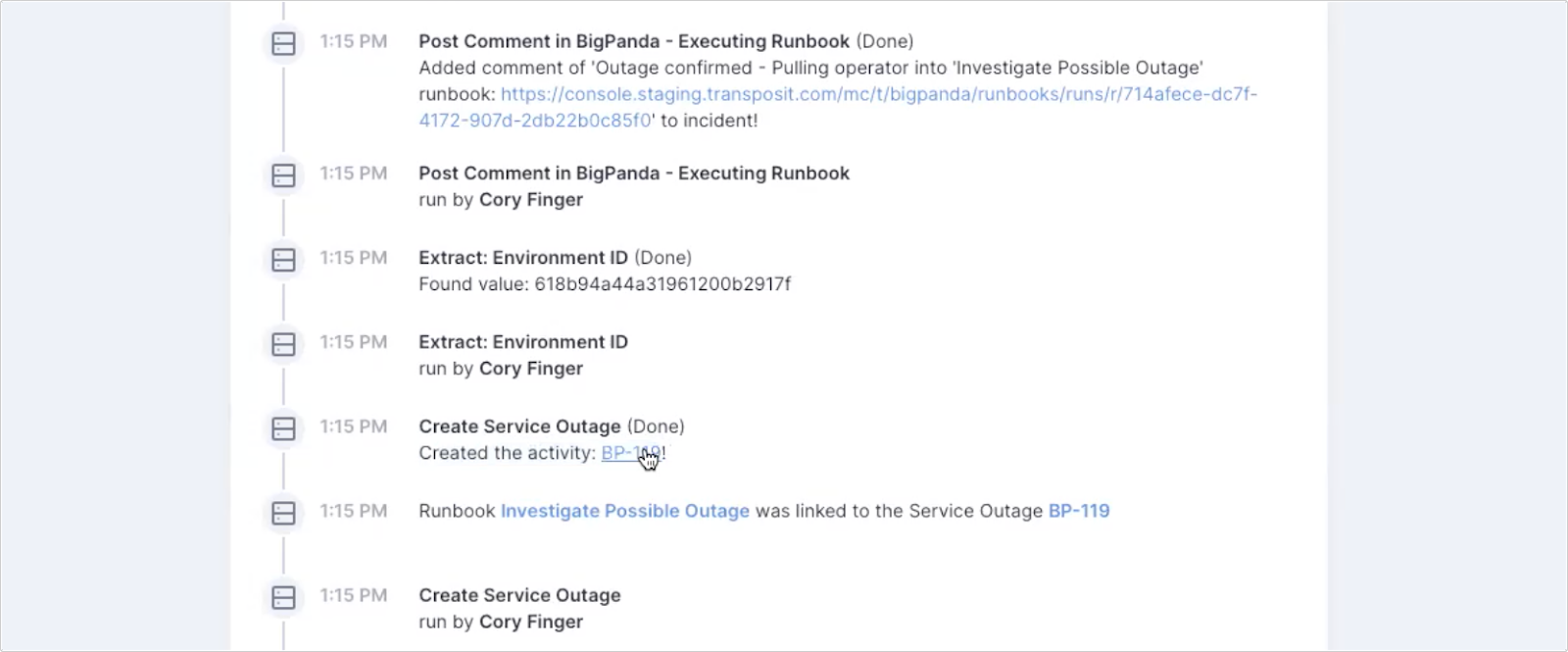
Within this Activity, a few things have automatically happened, including creating a Slack channel and pulling in data from the BigPanda incident.
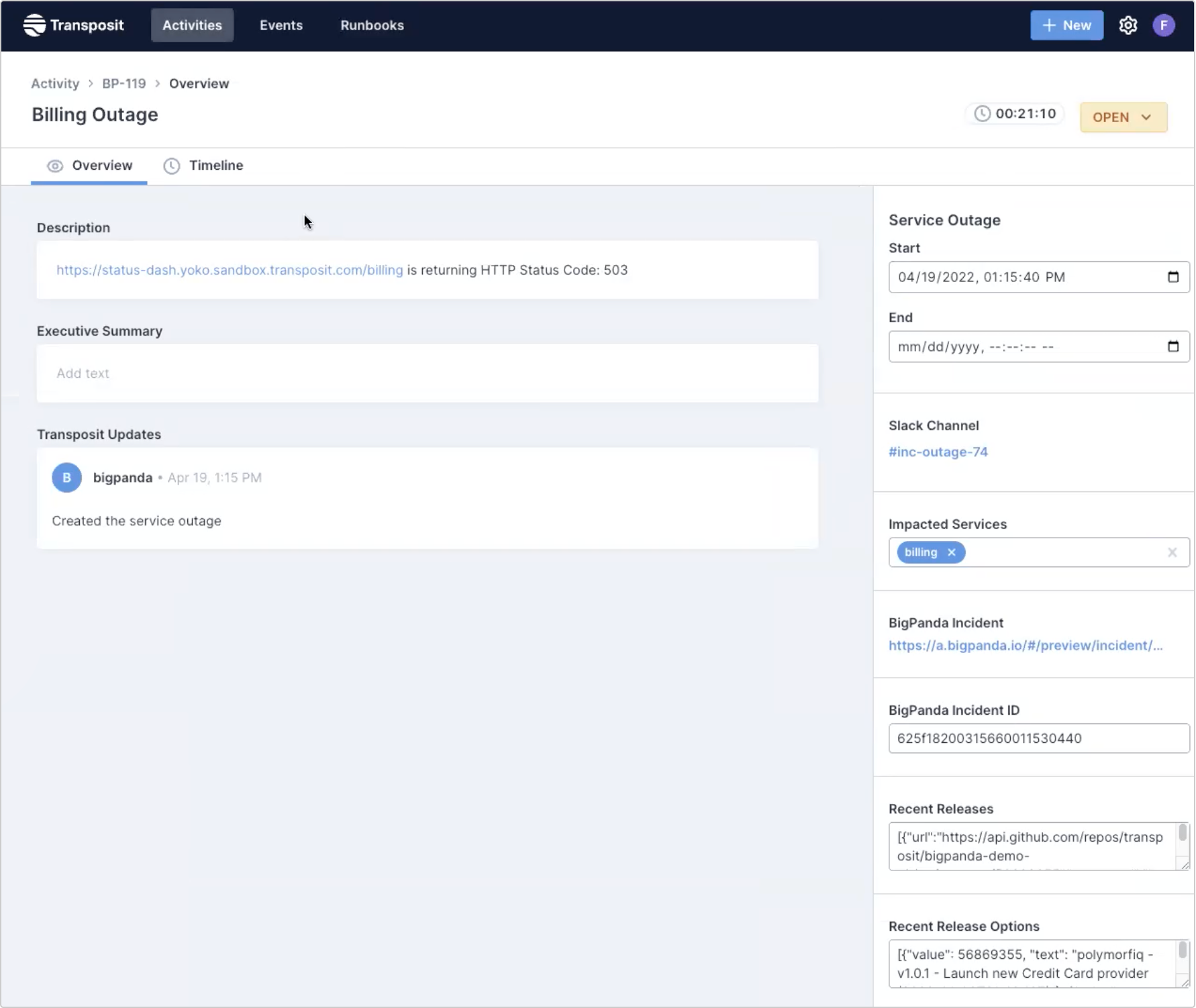
The entire remediation phase can be executed within Slack (or Transposit). The incident timeline is available in the Slack channel, creating the shared context teams need.
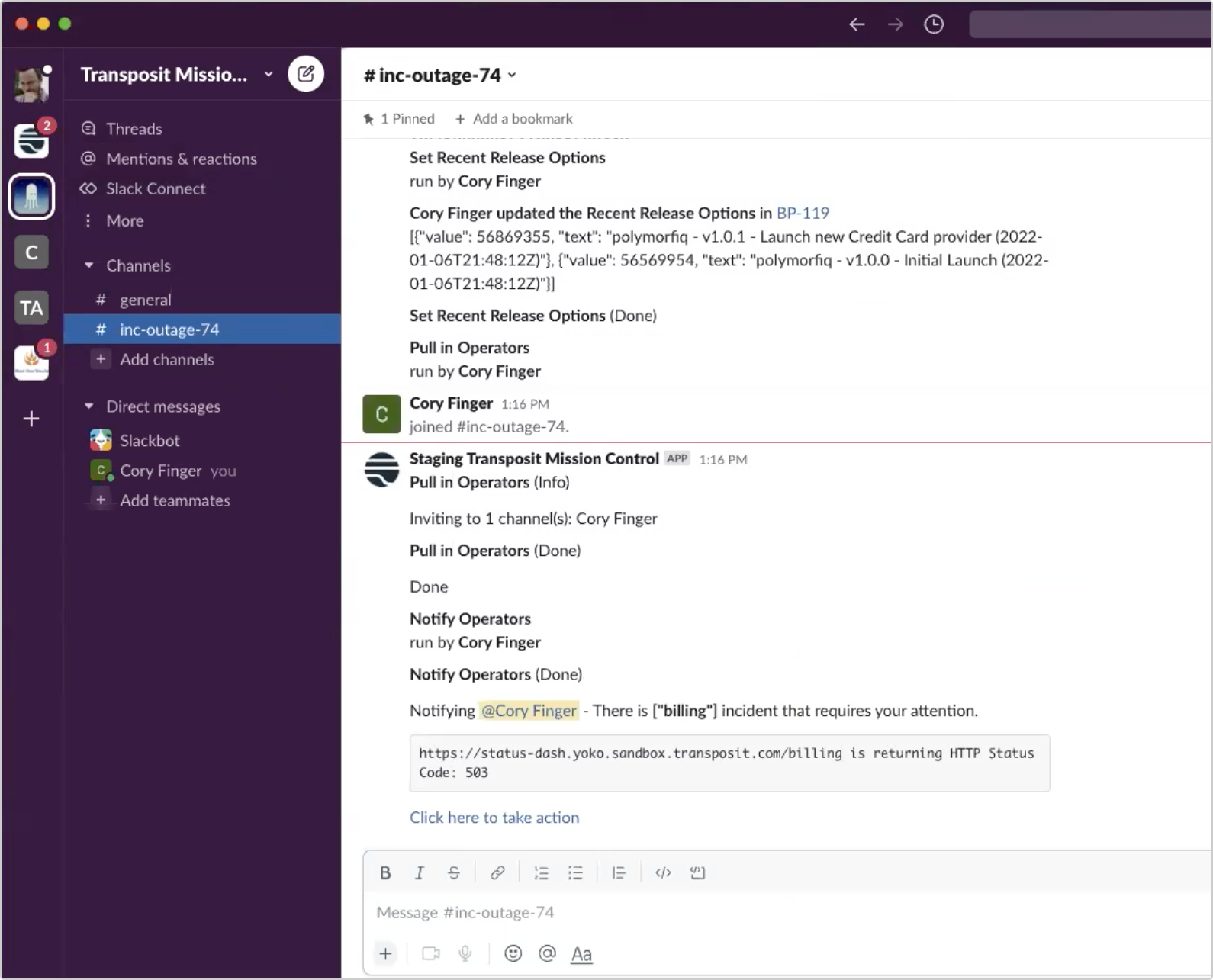
Pulling up our current workflow in Slack using the command /transposit, we see a series of actions that can be taken. As many incidents result from change, let’s first List latest releases.
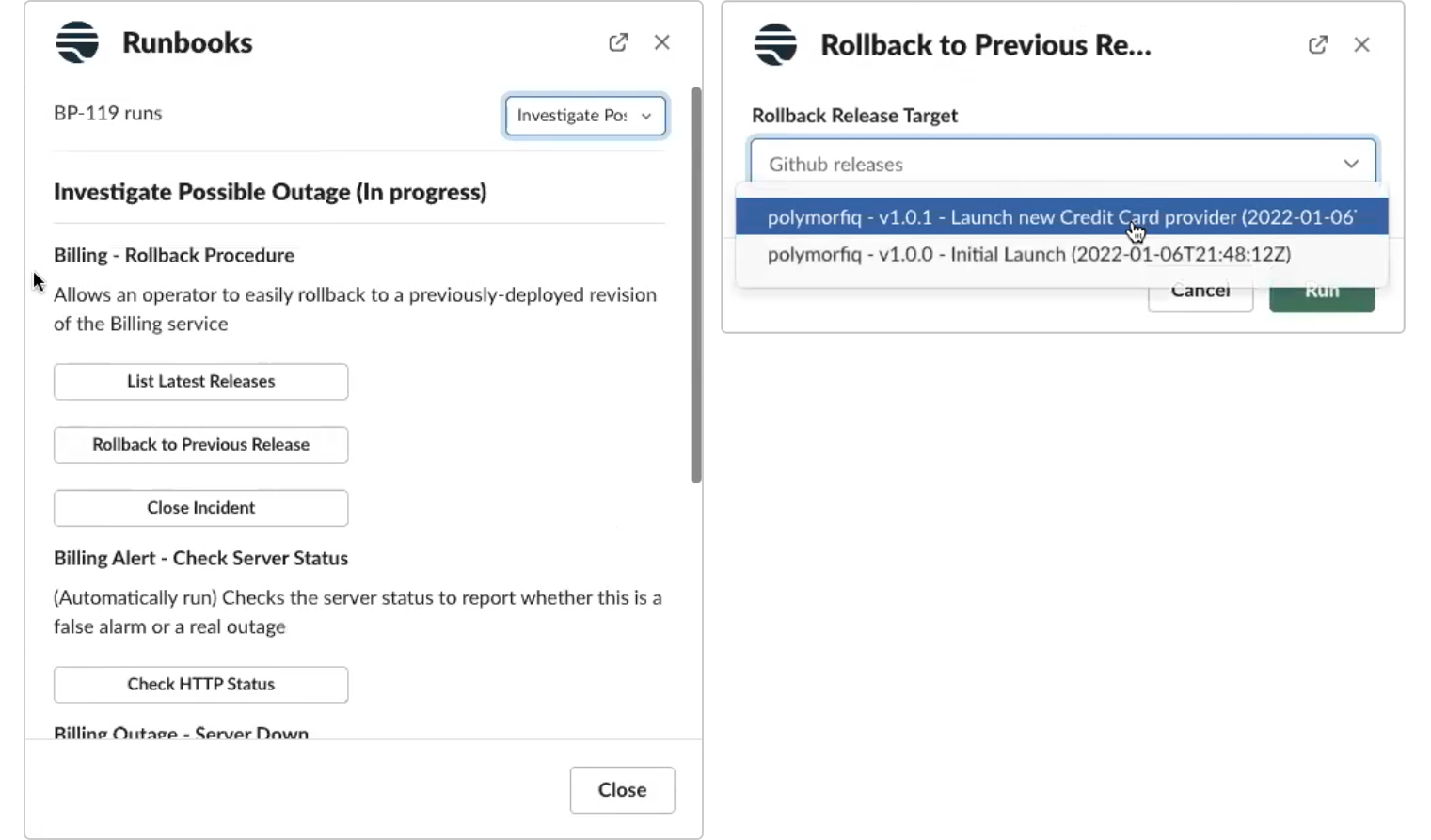
Looks like we recently deployed a new version. Now, the operator can use the Rollback to Previous Release action to roll back the recent deployment. This automatically executes a Jenkins job within the workflow to execute the rollback logic and get the server back to a working state. Of course, these could be any number of actions your team has decided to add to the workflow (Transposit has hundreds of pre-built connectors and actions).
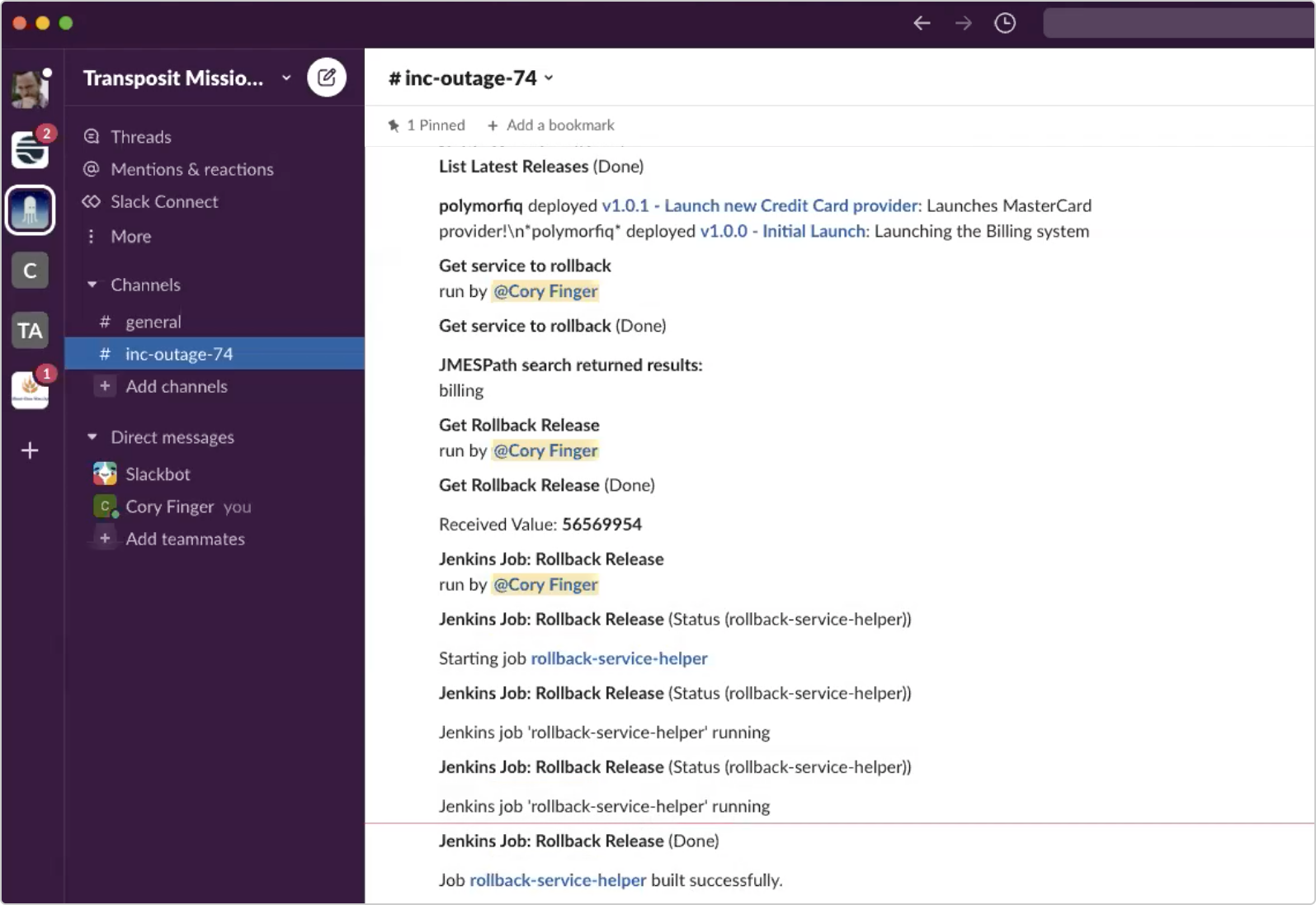
After taking this rollback action, let’s now check against HTTP status to make sure the server is online.
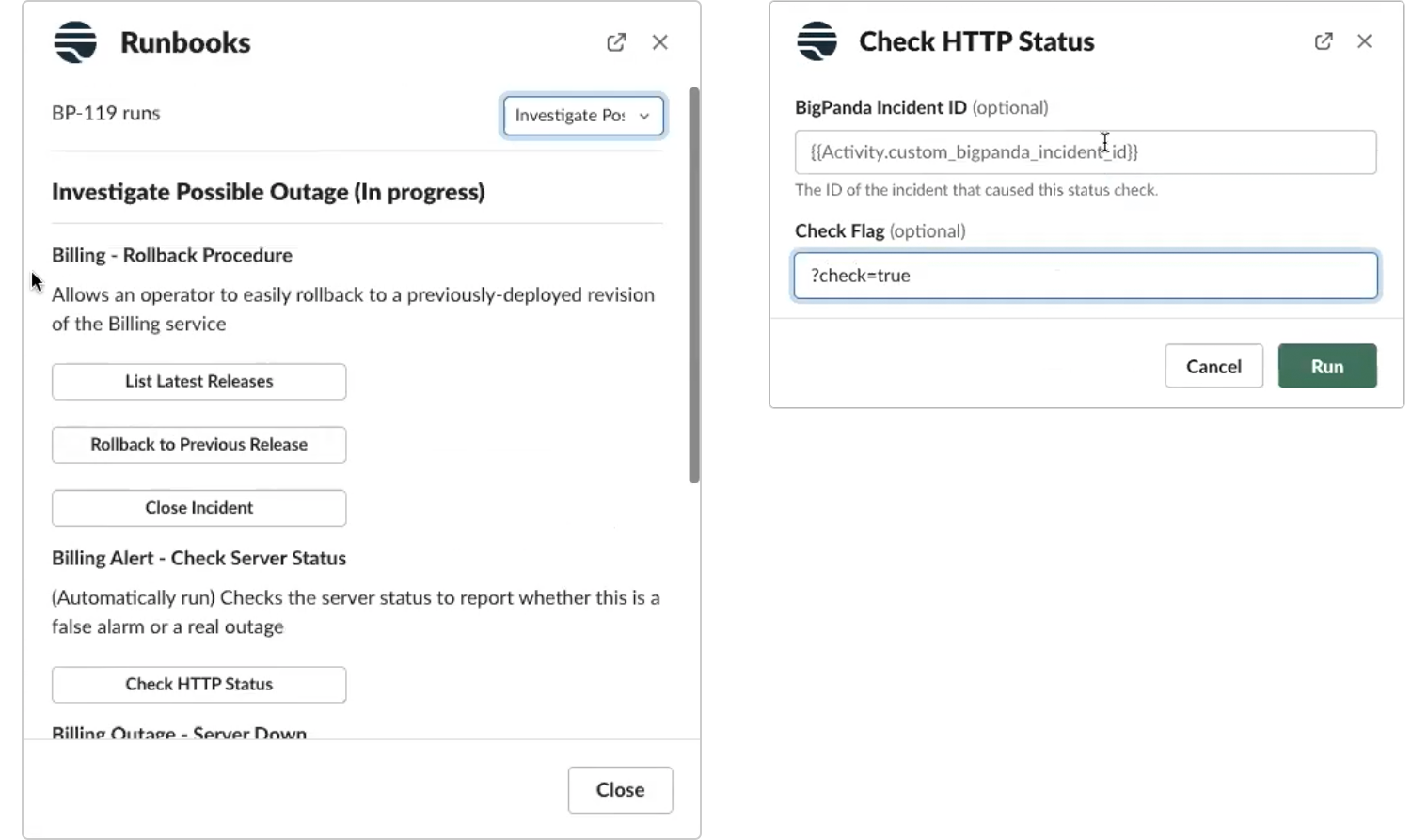
We can see that the status is now 200 and working properly. The incident is then auto-resolved once it’s verified that the server was online (reflected here in BigPanda).
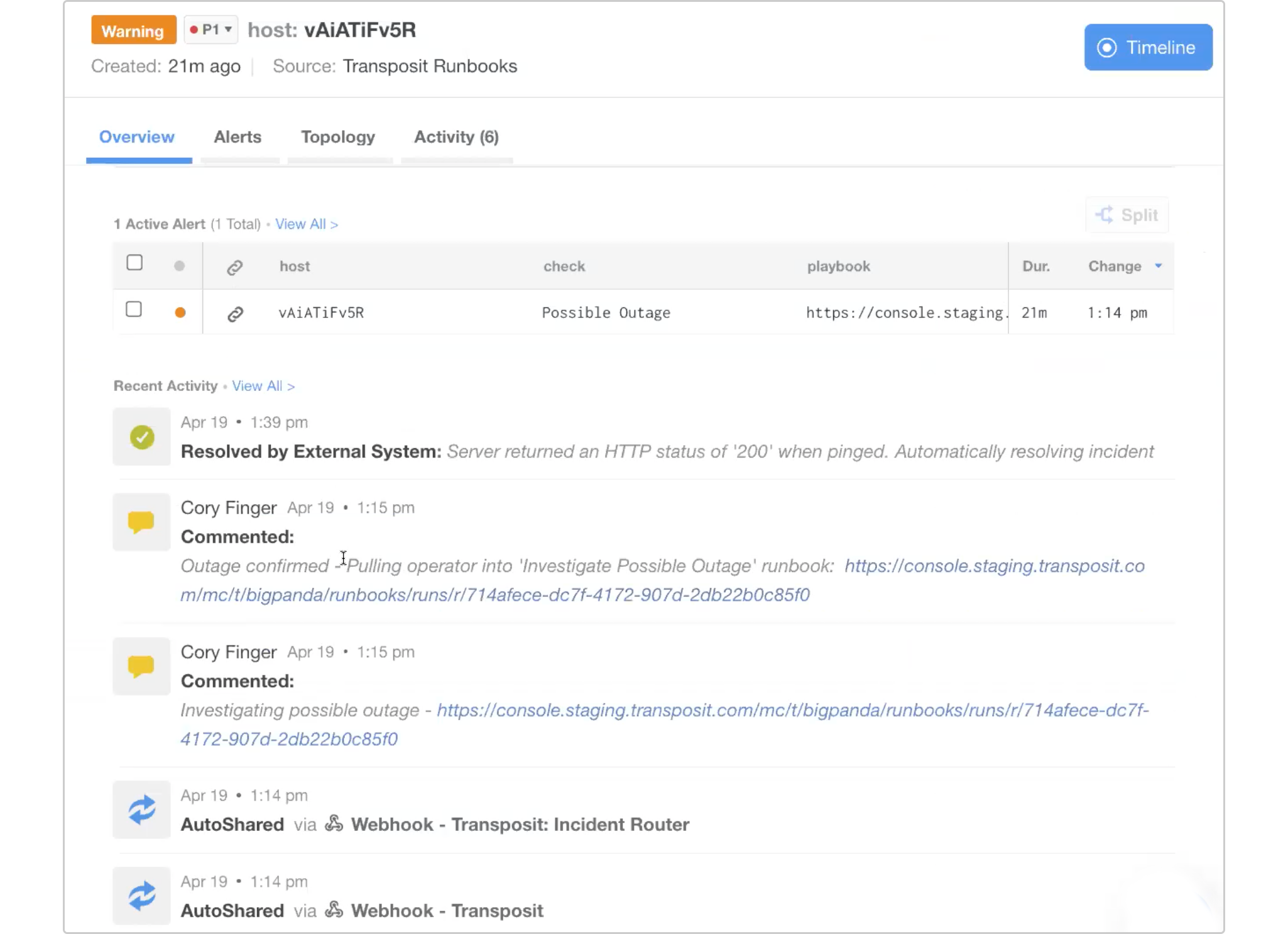
With just a few quick actions, we’ve resolved the incident and the server is up and running. All this is made possible with the enriched data BigPanda is able to pull in, allowing teams to instantly kick off the right automated workflow and restore service.



