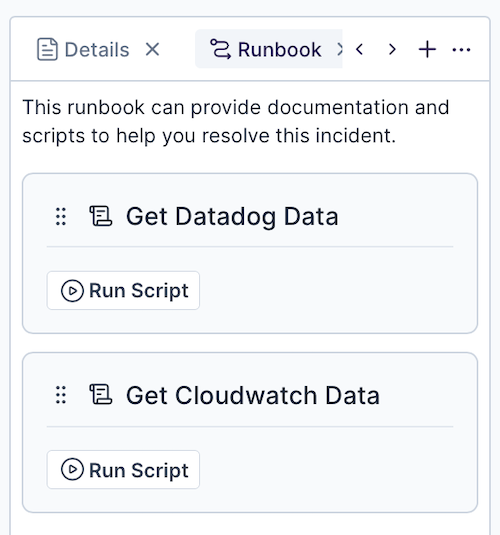
Each incident may have a runbook of automations available to the incident responder for resolving incidents.
The incident type selected by an incident responder may make one or more automations available from the start. If not, the runbook will be empty, as shown below.
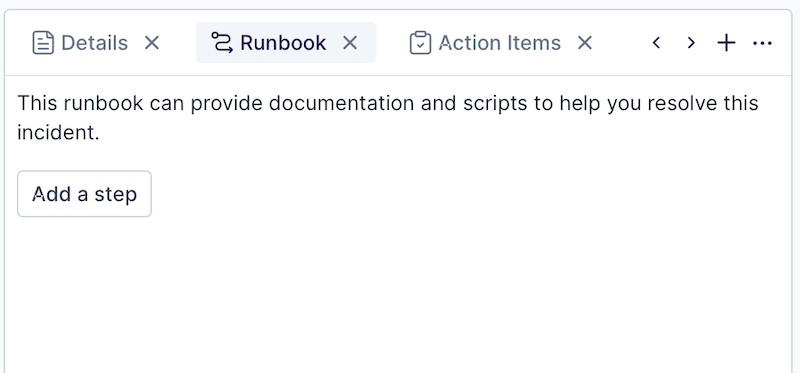
Adding a runbook during an incident does not persist it to its incident type. Be aware that a runbook can be created by an administrator as part of the incident type. An incident responder will then have access to the runbook provided by the incident type whenever a new incident is created.
Click Add a step to begin adding a new automation to your runbook.
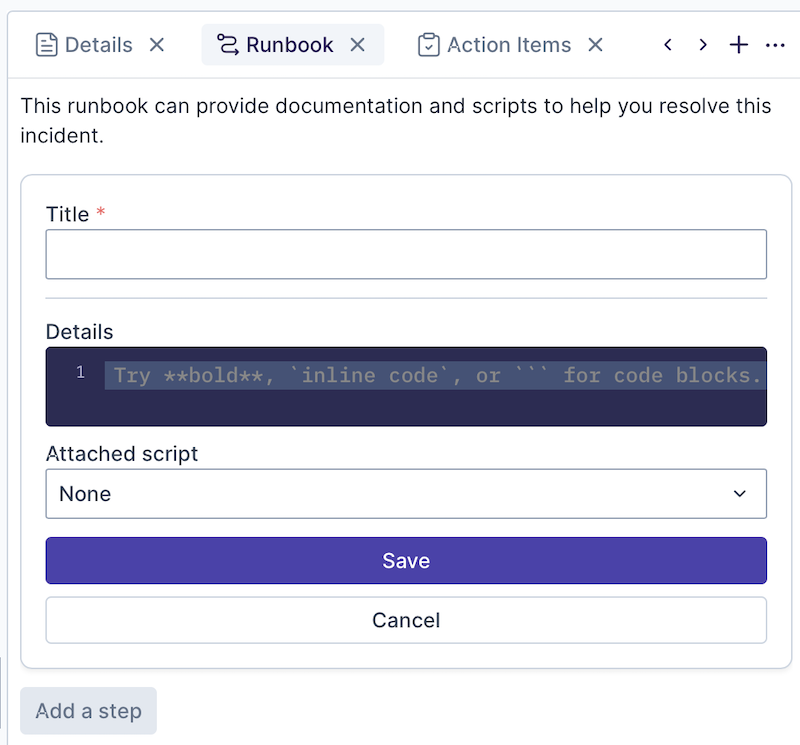
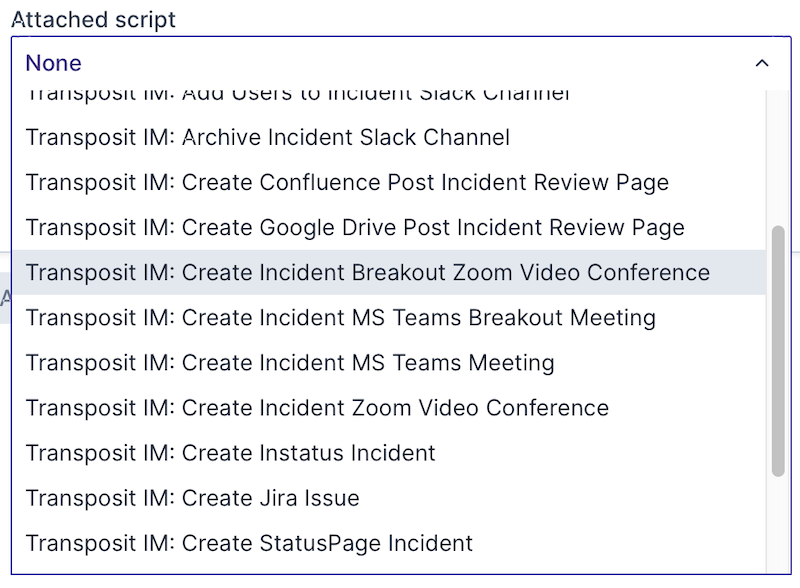
In the Attached script drop-down list, select the script you'd like to use to define the automation.
Once you've filled in all all of the automation's fields, click Save.
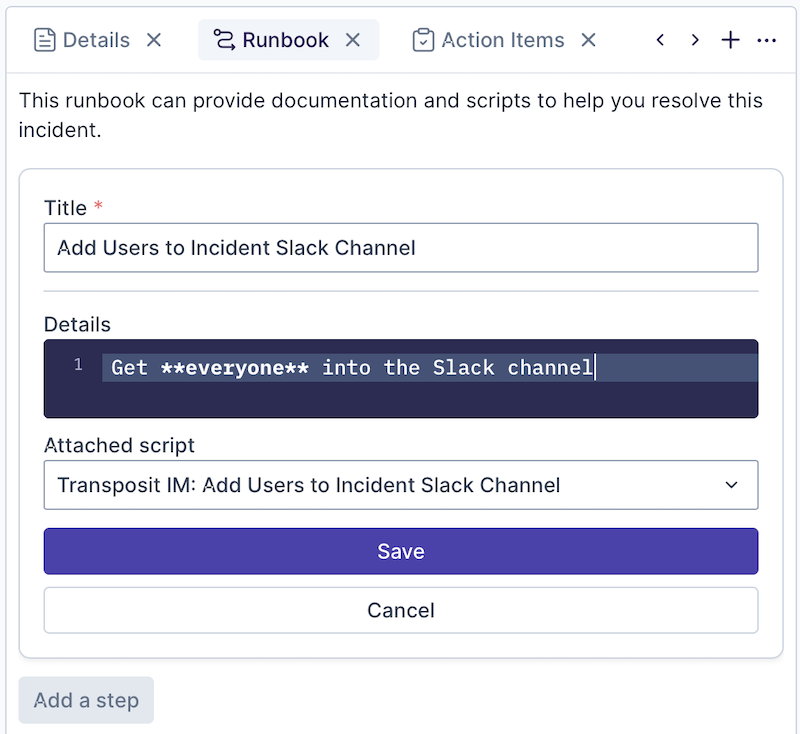
You now have a new automation added to your runbook, ready to be run to help resolve your incidents.