DevOps Spectrum of Automation: Artificial Intelligence
What is the right direction forward with AI systems in operations


With the growing popularity of using automation when operating systems, it is no surprise that the topic of machine learning (ML) and artificial intelligence (AI) comes up in discussions. Developers and engineers are always looking for ways to cut work that feels tedious, stressful, and burdensome. Who can blame them? In this blog post, we’ll explore what AI systems in operations looks like, where it came from, and whether it is the right direction forward. Also, we’ll look at other alternative strategies that give us similar benefits with less of the drawbacks.
ML/AI in operations
ML/AI are often used interchangeably when they are not the same thing. AI refers to the concept of machines mimicking human cognition, while ML is an application of AI. More specifically, ML refers to algorithms that automatically improve through experience. The experience is typically from sample data given to the algorithm. While ML is a common application of AI, I want to focus on a term that has been coming up more in software operations, AIOps. AIOps, a term coined by Gartner in 2017, is also an application of AI. Gartner describes it as combining “big data and machine learning to automate IT operations processes.” Lately, you might have heard more about AIOps in the software operations space, but what exactly is it?
When we refer to AIOps, we often mean things like predictive alerting, event noise reduction, incident auto-remediation, anomaly or threat detection, event correlation, or capacity optimization. Since it is a belief that software operations have moved beyond human scale, a promise of AIOps is to try to decrease the load on a human operator and offload the “people problems” that occur when trying to manage complex systems reliably. This is so that problems within our systems are found and resolved faster. For this post, we’ll mostly focus on events, alerting, and incidents. For example, instead of having an on-call engineer remediating an incident, it would be done by an AIOps tool. Another example would be using an AIOps tool that uses an algorithm based on the data you send it to provide event noise reduction because teams are being overwhelmed by massive amounts of event volume.
AI in the DevOps Spectrum of Automation
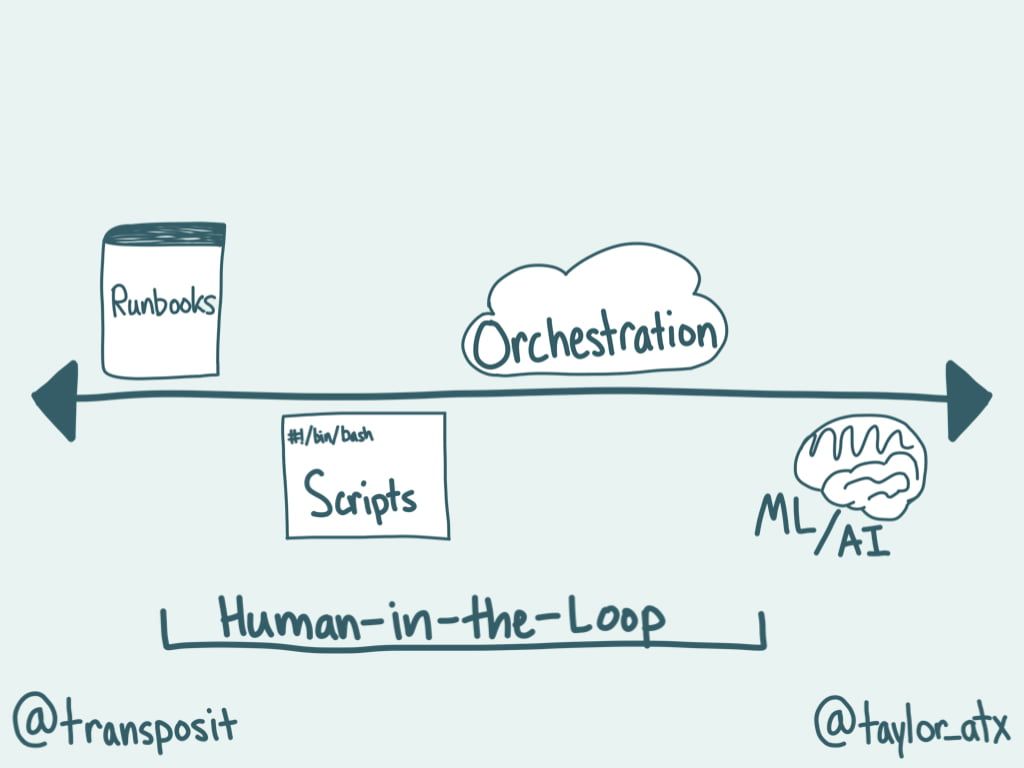
As Mary Branscombe said in The New Stack, “with orchestration and monitoring playing such key roles in DevOps, the emerging trend of using artificial intelligence (AI) to support and even automate operations roles by delivering real-time insights about what’s happening in your infrastructure seems an obvious fit.” In the spectrum of automation, AI often feels like the promised land, full of human-less fully contained, self-healing systems. While we aren’t there today, we think it is essential to establish what is on the far side of the spectrum, just how manual runbooks sit on the opposite side of the spectrum. It’s important to understand the bounds that we work within. Whether it is a good idea to sit on one extreme versus the other is another question.
The classic aim of automation is to move human work to machines, which is often the goal of using AI. On a theoretical level, it creates less work for human engineers. Less work sounds pretty awesome, but does AI in operations do that today?
Why AIOps is just not there yet
Often on-call engineering teams want a quick fix for their alert fatigue through automation, so some organizations are starting to AI for help. This is problematic for a couple of reasons. As Niall Murphy said in our recent event, “there is a lot of mental frameworks around the management of alerts and generation of pages that flows from inappropriate conservatism about what is actually contributing to alerts.” The focus on AI as a solution often ignores that there might be more significant problems with an organization’s alerting strategy and is trying to treat the symptom rather than the cause. Is the team getting burnt out on the large number of alerts that wake them up in the middle of the night with no action to be taken? Instead of using AIOps, the solution is often is better alerting strategies, such as error budgets and service-level objectives (SLO) driven alerts.
The second reason why this is problematic is that AIOps just isn’t going to properly fix many of the problems it aims to solve because of the data it is working with. This is similar to the challenges that ML driven applications face. As Danyel Fisher said so perfectly in another piece in The New Stack:
“The fundamental challenge of any AI system is that it needs to be trained on data. A machine learning system trains to find a boundary between “good” and “bad” examples, and so it does best when it can get a mix from each class. In other words, to train a learning system, we want a population of successes and a population of failures; we can then learn what the boundary between those two groups are. Unfortunately, that’s not how failing systems work. They tend to largely succeed, until they fail. That means there will be far fewer failure events than success events. Worse, the previous training examples should be useless. While any reasonably good ops team may not be great at anticipating and fixing future unforeseen problems, they can at least keep up with the last one. AIOps relies on known failure modes continuing to occur.”
As most can agree, allowing known failure modes to continue to occur is not a good practice for any organization, especially if you prioritize the health of our on-call rotation.
A third reason, especially for incidents, is what is going on in your system should not be a black box to your on-call engineers, but that is what AIOps pushes us towards. Think back to a painful incident that you responded to and how not understanding how the system handled the incident would have affected your ability to remediate. What if events or alerts were suppressed by an algorithm that you had little control over? This can slow down the response and resolution to an incident because the human operator has to understand what actions have been taken before they can take steps to remediate.
Pragmatic Alternative: Human-in-the-Loop Automation
AI systems look for repeatable and recognizable patterns, but an on-call engineering team usually wants to squash these patterns once they are discovered. Without the patterns, the AI is useless. As a whole, wanting more automation for your team is not a bad thing. How we interact with automation and develop it could use an update, though. Human-in-the-loop automation is a more pragmatic approach towards automation while reducing the load on team members. You can read more about human-in-the-loop automation in this past blog post, but to summarize:
Human-in-the-loop automation is when humans intersect at critical decision points while progressively automating their systems. Human-in-loop automation aims to find the right balance between end-to-end automation and human involvement. With only having end-to-end automation, you might find your attempts at automation to be unsuccessful or even harmful to operating your systems.
Human-in-the-loop doesn’t mean you throw the data out the window. As we talked about earlier, in most cases, you don’t need AI. For example, understanding causality requires much more knowledge than just your production environment can give you. You are often dependent on other services and systems, as well as other socio-technical problems to consider. This is why it is much more pragmatic to keep humans in the loop of your automation when operating systems. In Fisher’s The New Stack piece, he says the goals we are trying to accomplish using AIOps are a better fit for “tooling that allows you to flexibly pivot from these user-visible effects to the rich explanatory data behind it. Find the signal in the noise by both reducing the noise and by using tools that boost your signal.” This is an excellent example of being a human in the loop. Automatic data collection reduces a load on humans, while humans remain part of the loop as the investigators who presented with the data and understand the larger socio-technical systems they work in. They can identify and understand factors that AI can’t comprehend.
Having context-aware runbooks with proactive suggestions tied to alerts doesn’t require AI either. This is another example of why human-in-the-loop automation’s strong relationship with data is important. In the classic definition, it is a model that is being trained by a human. Operating systems with human-in-the-loop automation allows us to capture human actions that could potentially be used in the future and gives us a better understanding of how humans are operating in the system. This could be as simple as collecting data on what runbooks are commonly used with specific alerts. This could turn into a future proactive suggestion that might be useful to future on-call engineers responding to a similar alert.
As we’ve discussed in our blog post about human-in-the-loop automation, we still often need the human operator to respond to incidents because of the unique characteristics humans have. As Dr. Richard Cook says, operators “actively adapt the system to maximize production and minimize accidents.”
Conclusion
When trying to solve underlying problems you experience when operating your systems, it is vital to look at the actual problems and consider their causes before deciding to go to the far side of the automation spectrum. Make sure to explore all parts of the spectrum to see what might make practical sense for your case. Often there are ways to automate without going to one extreme or the other still progressively. This is the last post in this series about the DevOps Spectrum of Automation. I encourage you to read the previous pieces on runbooks, scripts, orchestration, and human-in-the-loop. By no means is the spectrum complete, but this should give you a good idea of waypoints along the spectrum to guide you on your journey of DevOps automation.
Related Articles

Back to Basics: The Core of AI's Future Lies in Mastering Integration

AI Recommendations: Ask Anything About Your Data for Instant Guidance

Streamline Incident Communications With AI-Generated Summaries & Key Events
