Creating an API from HTML: Scraping Amazon Reviews into Google Sheets
When there’s no API and text is all we have, never fear! Apify can turn any site into an API and Transposit lets you plug it into the other systems you care about

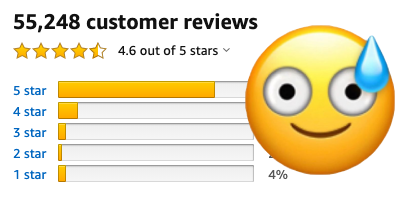
Sometimes, we run into websites and online services that have a bunch of data that would be really useful to have, but there isn’t a great way to access and use that data for that use case that would save us a lot of time on the daily. This used to be a much more common problem years ago, before nearly everyone and their cat had published an API (including a Chuck Norris fact API), yet there are still some popular websites that refuse to budge.
Amazon product reviews are a great example. It’s extremely interesting data that Amazon doesn’t expose through an API. In the browser, you click “See all X reviews” link, which shows the first ten reviews before you must click next review endlessly. If the product only has around 50 reviews, this isn’t too unreasonable, but say you are an author of a book with thousands of reviews. That is hundreds of pages of reviews to sort through to see how people on the internet feel about your art. The Amazon Reviews API I’d want doesn’t exist. So we must resort to using a different solution.
Enter Apify
Apify is a powerful platform where you can turn any workflow on the web into an automation, through its vast network of ultra customizable actors. I’ve only been scratching the service by using their standard Web Scraper as my actor (which I used in my Pridebot post), but there are many more to choose from. Apify and Transposit work well together to create apps with and without their own APIs.
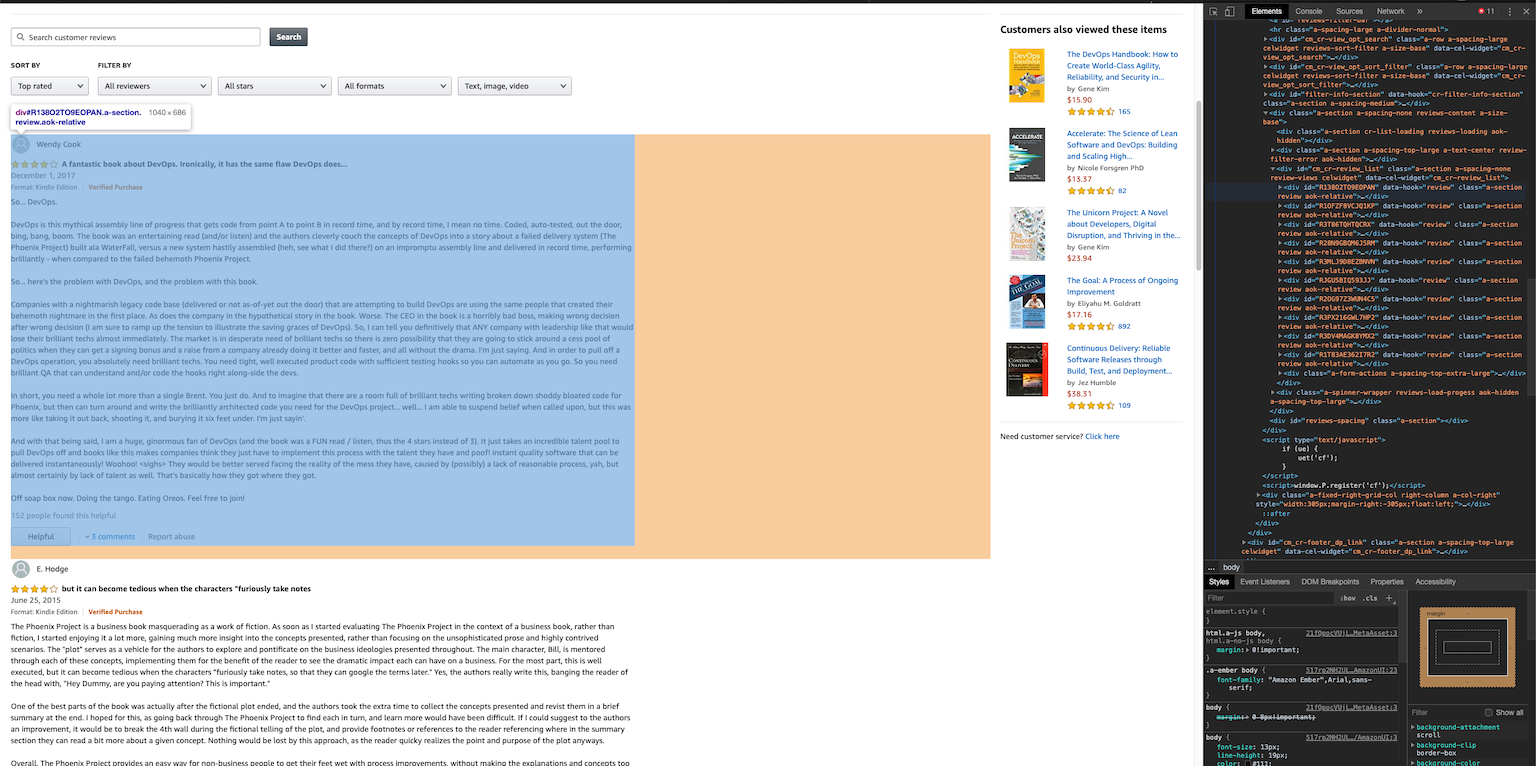
Amazon Reviews are a very popular topic people want to scrape, so I was able to find some resources to point me in the right direction of building a task to do just that. With a quick search, I found a gist from Scrapehero that showed me which HTML elements I needed to find with JQuery, as well as the tags for the link selector, which will help the scraper know which links to look for to go on to the next page. My Apify code ended up looking like this:
// Link selector: li.a-last a
async function pageFunction(context) {
const { request, log, jQuery } = context;
var $ = context.jQuery;
var result = [];
$("div.review").each(function() {
result.push({
rating: $(this)
.find("span.a-icon-alt")
.text()
.charAt(0),
title: $(this)
.find("a.a-size-base.review-title")
.text(),
content: $(this)
.find("div.a-row.review-data span.a-size-base")
.text(),
author: $(this)
.find("span.a-profile-name")
.text(),
date: $(this)
.find("span.a-size-base.a-color-secondary")
.text()
});
});
return result;
}This will scrape through all of the reviews, and placing each of the ratings, titles, bodies, authors, and dates into their own column in the dataset collected by Apify. It will take some time to gather the results, especially if there are a large number of pages to sort, but still significantly less than manually collecting the data oneself, and also keeps it in a readable data format as well.
If you aren’t lucky enough to have somebody figure out which HTML elements you need to look for, you’re going to have to dive into the HTML yourself. Lucky Chrome and Firefox have pretty good tools for this with Inspect (Element), where you can hover over elements to see what they are creating in the webpage. Here is an Apify article that goes a bit more in depth about how to get started so that you aren’t doing it blindly.
Putting it all together
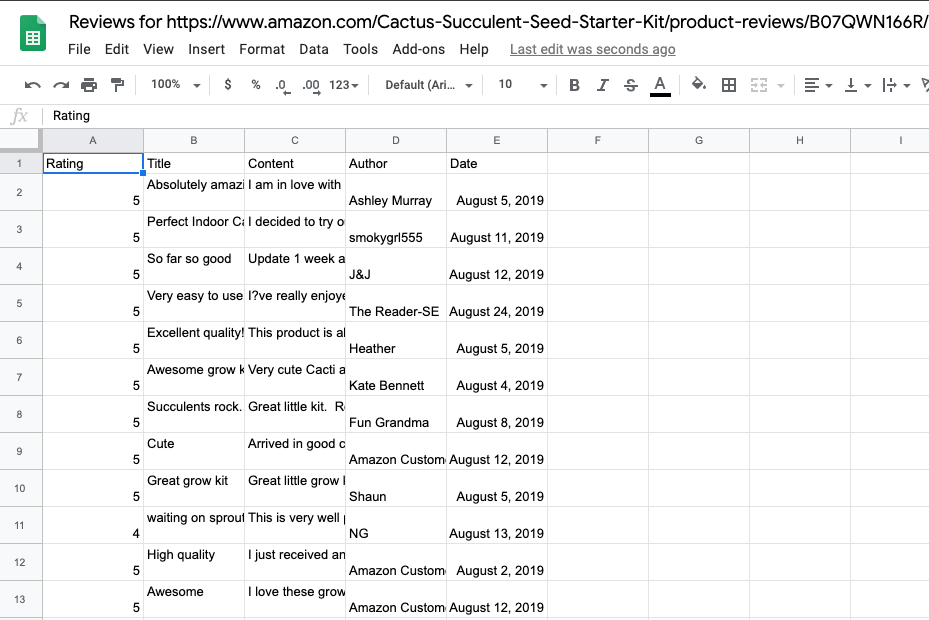
While with some use cases just a dataset of scraped data is all you need, most of the time you will want to manipulate or place the data in a more accessible location. Especially if this data will be used by people in various backgrounds. Additionally, it can be nice to use an interface outside of Apify to change some of the variables before scraping, such as the starting URL of the product to scrape.
In Transposit, the Apify connector calls the scraping process with a custom Start URL. The data is then passed into Google Sheets, where it is placed in bulk onto a fresh sheet that we created at the beginning. The URL of the sheet is returned at the end of the function for you to open and view. All at the click of one button.
Of course, this is still mostly a bare bones implementation of a scraper, but there are many options to go forward from here. You can add another integration that will let you to call the scrape and access the data in your desired workspace. Examples of this could be a Slack slash command, a Twilio text bot, or an email solution of your choice. These solutions will message you appropriately with the link when it is done to view at your own schedule.
The API you dreamed of using
The world is moving to APIs and Transposit connects you to those APIs. For sites that can’t, won’t, or don’t give you programmatic access Apify is a life saver. APIs work best when they work together. Scrape a conference agenda and load it into your Google Calendar. Grab a catalog of marketplace items and post it a Slack channel. Or in my case, extract review information and organize it into a Google Sheet. There is always a way to create the Transposit app you want and gather information you need. Go ahead and fork my app and create the web automation that will save you time and energy. Modify it to do something different with the data. Or Apify your favorite site and connect it with your favorite API using Transposit.



