Human-in-the-loop workflow automation
The power of automation is increased by bringing humans into the loop.


Manual workflows are productivity killers. Automation has become our North Star. But many workflows can only be partially automated; they may benefit from or require human intervention. APIs give us the levers we need to build great automation. Applications provide the interfaces that pull humans into the loop at critical junctures. Composition is how we turn those APIs into apps that integrate disparate applications, simplify workflows, notify people, and respond to interactions. Apps that allow for human-in-the-loop automation can help you efficiently build apps and bots that automate the tedium and let humans add maximal value.
Automation
Even though I love APIs, I’m going to instead start out by discussing automation. It probably goes without saying that businesses are constantly looking for ways to improve efficiency with automation. Having a bunch of people do manual tasks is terrible. On top of the time it takes to do the task, there’s all this overhead: tickets to track the work, workflows to coordinate hand-offs, and managing delays between hand-offs. These manual workflows are prone to human error, it’s really easy when people are involved to mistype a name or hit a wrong button. And so we look to computers to do these tasks for us.
Software as a service (SaaS) is a part of this; we are living in the golden age of SaaS. Companies are adopting more and more SaaS, which has been a boon to productivity because we get all of these specialized apps to manage various aspects of our business. But, it can also create silos. Each of these applications is its own data silo. Tasks that used to live in one place get split between different applications, and, often times, different users for each of those applications. But even worse, the junctions between these applications often mean manual workflows: humans typing data from one application into another.
APIs give you the power to automate. And so, with this increase in SaaS, we see a corresponding increase in demand for automation. Luckily, SaaS providers are increasingly understanding that applications need to be platforms. And that they need to empower the users of their platforms by providing APIs. APIs give you the power to automate. APIs allow you to programmatically call applications so that you can turn these manual workflows into automated ones.
Currently, the majority of the automation tooling we see is focused on what can be fully automated. That is, automation that can be triggered and completed without the need for human involvement. This type of automation is appealing because of its simplicity. You don’t need to provide an interface because there is no human interactivity.
Unfortunately, this type of full automation limits the set of tasks you can automate. A lot of tasks need just a bit of human input and guidance. Customization can also be more complicated because you need to do all the configuration up front, effectively spelling out rules for all the possible conditions you might encounter. And as much as humans try to anticipate all possible outcomes, reality is often times more complex and can be full of surprises. So these automated workflows can be fragile and error prone.
Human in the loop automation
So how can we get the efficiencies of automation in more of our workflows? Fortunately, there’s something called human in the loop automation. Human in the loop automation is when you have automation, but at various points along the way, humans are given opportunities to interact and influence its direction.
So let’s take a common use case where you want to automatically create a new record in your marketing system when a customer signs up for your product. And let’s say you want to annotate the referral source in your marketing system. These referrals come from lots of different sources like a google spreadsheet that someone is tracking events like today’s or a service like Google Analytics.
The problem is that records in different systems are often not exact matches. If you were to fully automate this workflow, you’d likely end up with inaccurate data and a massive data cleanup project for later.
But using human in the loop automation, you can automate collecting the data and then present it to a person. So maybe you notify the marketing team that a new customer has signed up, and give them some rough matches for referral sources. Now a person can quickly select the correct referral sources before resuming the automation. We’ve both made it a lot faster for people to match up referrals maybe by using some AI to find likely matches, but we’ve let the humans enrich the ai with some additional judgement, thus massively improving our data quality.
It’s not without challenges
But with humans in the loop, we introduce some new challenges. One challenge I alluded to before is the need for interfaces for interactivity. This can be a challenge because designing UIs is time consuming and hard. But also because you want to bring these interfaces to whatever system of engagement is appropriate for the person’s role. Otherwise we might be exacerbating the problem by introducing yet another application for them to deal with. So that means we need to be building actionability into interfaces like Slack for engineering or Zendesk for support.
The other problem is how do we identify who is interacting with the workflow. it is much better if we can have individuals identify themselves for each of the underlying services rather than relying on some shared API key. We can also automate a lot more if we can give each person access to everything they can access in the underlying system rather than the lowest common denominator of what everyone in the workflow has access to.
With human in the loop automation, rather than replacing man with machine, it’s about lettings people focus on the tasks where they can add the most value and letting the machines do the rest.
Common patterns
Now that we understand what human in the loop automation and some of the challenges around it, I’d like to walk you through some common patterns it can take.
The free pizza button
One of the most basic forms is having the human be the trigger. I like to think of this as the free pizza button. Imagine you’re customer support for a pizza place. Often times when someone calls in to complain, you want to keep the customer happy and give them a free pizza. But this process might actually take the customer support specialist a lot of time if they have to file a report with the customer information to document the complaint.
But if we were to fully automate this process and give a free pizza every time someone complained, people would probably figure it out and it would be free pizzas for everyone! Ideally you’d want to let the customer service rep do what they do best: determine who should get a free pizza. And then give them a single button to push and then automate the rest.
Human detective
Another common pattern I like to call the human detective. Here we notify a person when there is a problem. And then we provide them tools to investigate the situation and determine the best course of action. And then make it easy for them to take action.
Let’s take the example of developer builds again. Developer builds can be flakey. They can fail for a number of transient reasons like network connectivity issues. But it would be inefficient to automatically retry every build. So one hybrid approach might be to notify the developer that the build has failed. But let’s not stop there. Let’s also provide tooling to help collect useful data to analyze the situation, like searching the build or deploy logs. And then give them quick access to actions like retry the build or revert the change.
Now, instead of the developer having to see the notification in slack, go to their CI/CD system to find the logs, then manually retry the build or revert the change in git, they can now do all of that from one place.
Approvals and the human sanity check
Sometimes you want human accountability, sometimes machines aren’t perfect. At Transposit we use Google Hire as our applicant tracking system. They offer a one click way to email a candidate with a response. But they automatically extract the candidate info from their resume.
This has led to some embarrassing cases where I’ve emailed candidates with their name in all caps. Having that final approval or human sanity check not only gives you accountability, but it can also save a lot of embarrassment.
All about the applications
What we are really talking about is building applications that enable business automation. There’s a class of problems that trigger and event based workflow automation tools can solve, but for the rest, we need to build applications. Applications provide the interfaces that pull humans into the loop at critical junctures.
And what makes this class of applications unique is that they are really about integrating and connecting other applications through APIs. Our job as developers is increasingly about building applications to improve workflows. And building these applications is increasingly about connecting and combining APIs.
But connecting and combining APIs together rarely looks like assembling together lego blocks. APIs unlock possibilities, but they can be a pain to work with. Each is a unique snowflake – who hasn’t has spent more time reading the nitty gritty of some API documentation than seems reasonable or that they should have to?
An imperfect abstraction
APIs often reflect how the service owner thinks about the data and how their data infrastructure has been laid out rather than the way developers want to consume these APIs. For example, how they have chosen to cache or index their data dictates what API calls are available. One manifestation of this problem is often referred to as the N+1 problem, where what should be one request to load a list of items turns into N+1 requests since you have to do a follow up request for more information for each item in the list.
Another example is pagination. Many of you are familiar with this problem where to get 100 results, you get the first 25, then the next, etc. But there are so many different mechanisms for how various APIs implement pagination. One of the most incredible examples of this I’ve seen is the Slack API. They have 5 different pagination mechanisms. In the same API. Living side by side.
Anyone have a guess what their answer to this problem is going to be? Yes, a 6th pagination mechanism: one to rule them all.

This same lack of standardization is also true with authentication. Here the situation is getting slowly better with OAuth2, but there is still a lot of legacy authentication systems out there, and even with OAuth2, there is variation between implementations. Not to mention, dealing with the OAuth handshake and storing those credentials is a ton of work just to get started with any API.
And then there are things like rate limits and retries. As the API consumer, once you make your code work with APIs, the result usually looks like a convoluted mess.
Complexity++
But this complexity problem is so much worse in this API world because we aren’t talking about complexity within a single application. We are talking about the complexity of interactions between a bunch of different services that communicate over the network.
This effectively means that all application developers in this world need to have some general competency around distributed systems and security. For instance, they need to understand how to code against unreliable networks. They need their code to be resilient to long latencies of network requests. They need to know how to write code that throttles requests appropriately to not overwhelm the underlying systems and trigger rate limits.
At Transposit, we call this problem of having to write lots of glue code to connect and combine data from all these different services, API composition. And, the reason we spend so much time thinking about this problem is because the number of APIs keep increasing, and the complexity of composing logic on top of all of them scales exponentially the more APIs and services your trying to compose.
On top of all the complexities composing APIs, there’s an additional challenge in that every SaaS application has its own concept of identity. That means that when you build applications on top of them, you need to also find a way to link together these various identities so that you can authenticate the underlying API calls.
What’s the solution?
What we’d ideally like is to get out of the business of encoding in excruciating detail the minute interactions of each API. We’d like to operate at a higher level, to be able to explain our high level intent: What we want done rather than how to do it.
At Transposit, we do this using both SQL and a JavaScript API, but I’m going to show SQL because it really showcases what I mean by focusing on intent and not mechanism.
Take a simple SELECT statement. Here the developer only needs to think that they’d like to fetch a list of items.
SELECT * FROM api.list_itemsBut even in this very simple example, there’s a lot of mechanism we abstract away:
- How do I authenticate against the service? Do I need to sign the request? How do I re-auth after the access token expires?
- If I’m not authorized, will I get a 401? Or an error code in the json?
- What HTTP method does the API call?
- What version of the API should I use?
- Is that parameter a query parameter or a header or path parameter?
- Is that parameter required?
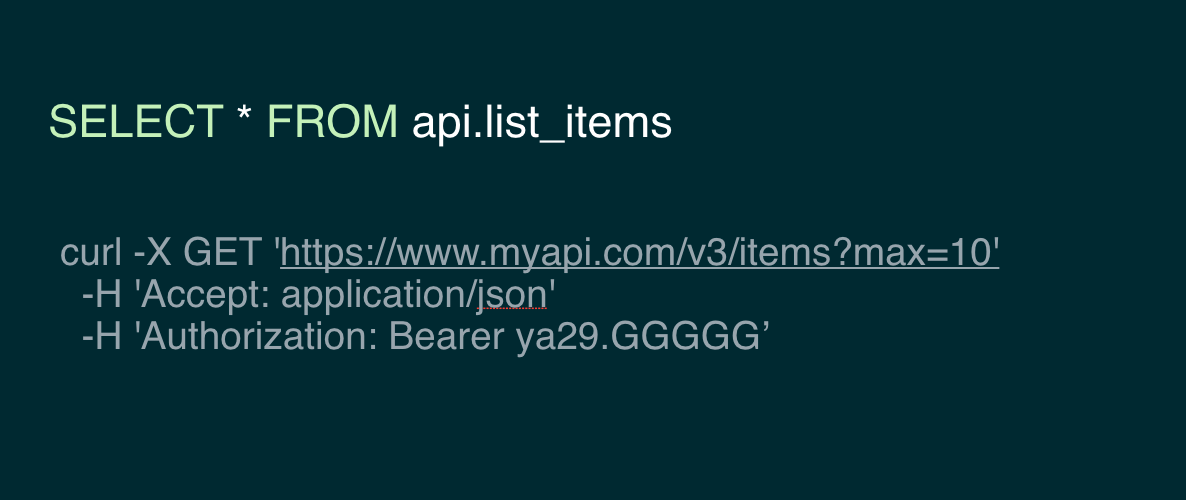
And then imagine something a tad more complicated: I want to fetch more results. The developer can just specify the number of results they want through a LIMIT.
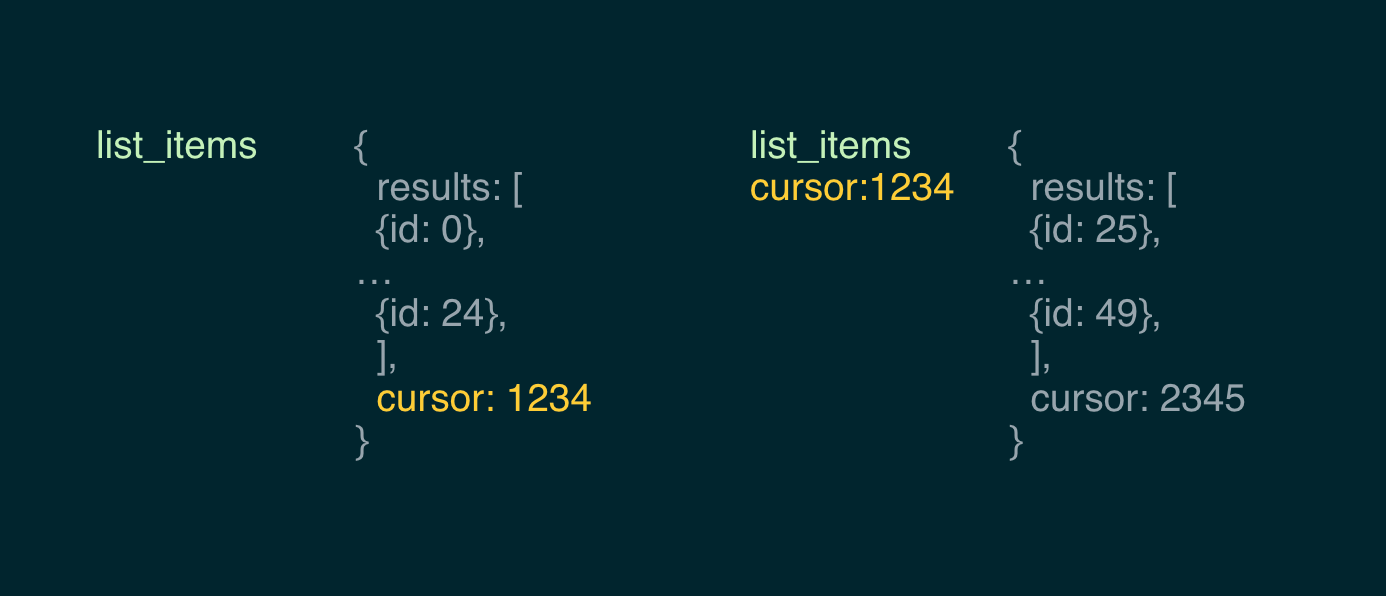
SELECT * FROM api.list_items LIMIT 100We can abstract away the mechanism for getting 100 results: grabbing the cursor from the result, pass it through to the next request, etc.
Even authentication can be abstracted away. Here you can see that there are two handles that point to Google Calendar. One handle is bound to your personal identity and the other to your work identity. So once again, you can focus on the intent: which calendar am I trying to call? You don’t have to worry about the mechanics of which credential to use and how to properly apply that to the API call.

Application examples
Where’s my commit?
The first is something we call “where’s my commit”. We have a tiered release process where commits get automatically deployed on our internal build. Then once a day, we cut a release to staging, where it bakes for 24 hours before being deployed to production. I often want to know when a specific issue recorded in Jira will be available for testing.
Before the process involved me asking in slack and an engineer going to Jira to a git sha, then to ECS, etc. So an engineer built me a Slack command where you can give it a Jira id, and it will tell you where it is in the release process.

CircleCI
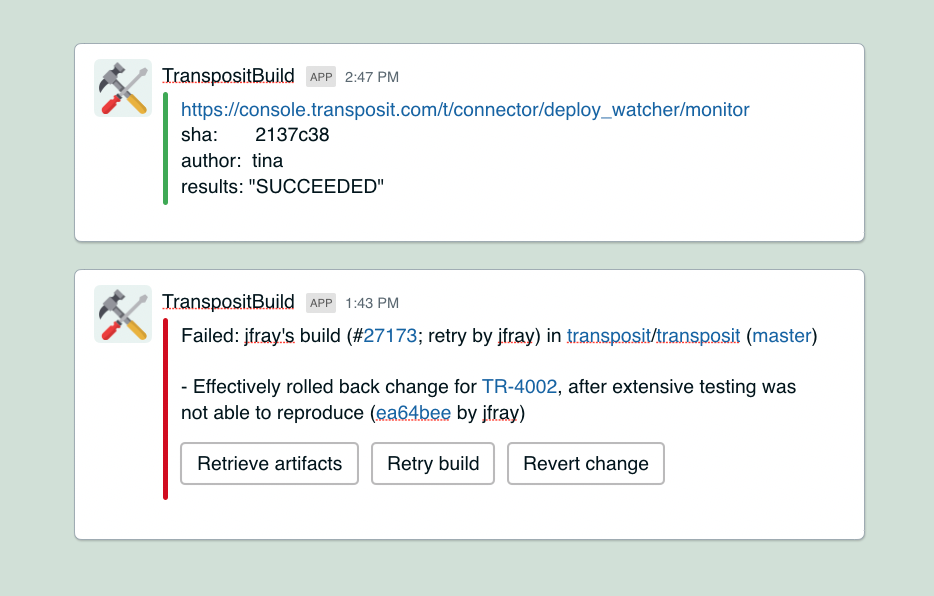
At Transposit we use CircleCI for our build and deployment system. The default CircleCI integration with Slack is pretty limited – it allows you to configure a channel where it posts build updates. We decided we wanted an enhanced integration with quick actionability.
So on build failures, we added buttons to the notification. One that lets you retrieve build artifacts as well as buttons to retry the build, or revert a change if needed.
DevOps Oncall channel
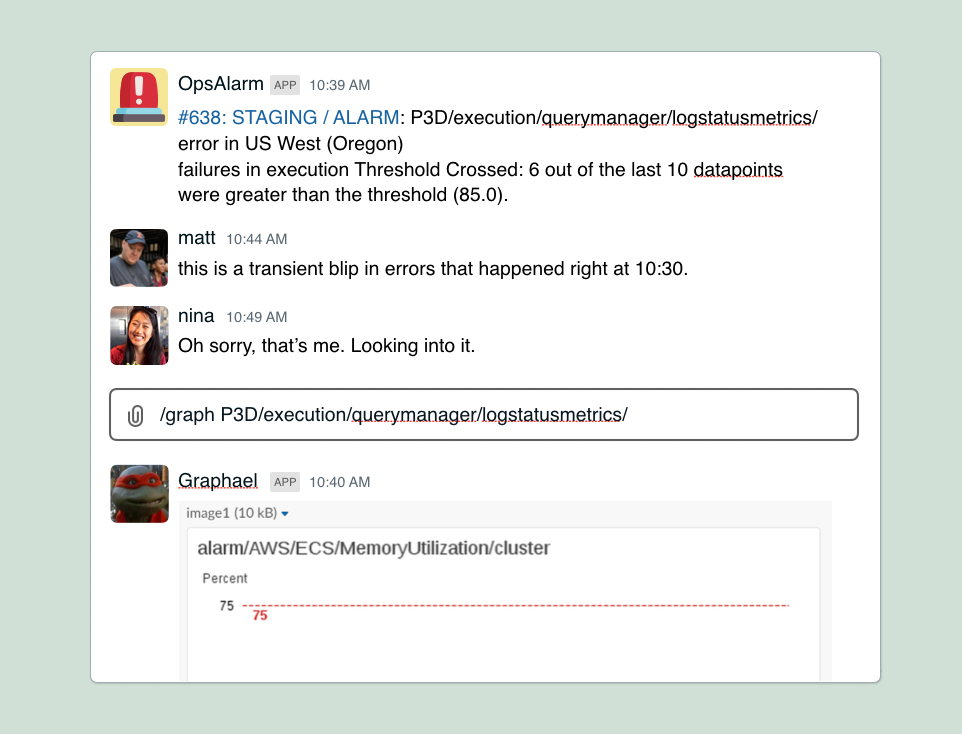
Like many eng teams, we use slack as the hub for our oncall operations. So when alerts fire from our monitoring system, it posts to an oncall channel.
Here, the SRE and engineering teams can chat and collaborate about what’s happening. But one common problem is making sure everyone is looking at the same set of metrics, and integrating those metrics into the discussion. Before this would often look like people posting links to dashboards, or someone manually taking a screenshot of an alert and uploading it into slack.
So we’ve added a slack slash command that will pull a screenshot of the metric directly into the oncall channel. And then as a bonus, we’ve made it easy to create a Jira ticket from within slack. Again saving all the context switching between applications and pre-populating a lot of information so that we can link together the conversation in slack with Jira.
Oncall chatbot
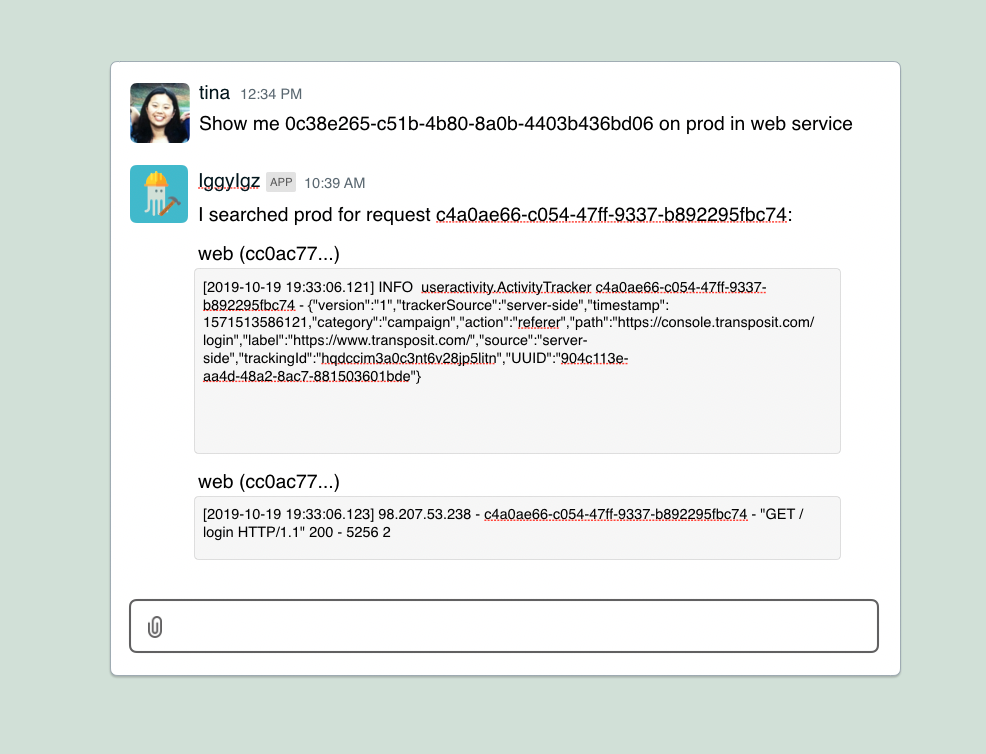
We built this interactive chatbot named after our mascot Iggy. We use Google’s DialogFlow to parse questions you might have while investigating production issues. So we can now ask IggyIggz to show me logs for a particular request.
In conclusion
We need to build more applications to integrate all of our tools. These tools empower us with a ton of APIs, giving us super powers, but each one of them is unique with its own steep learning curve. Human in the loop automation lets us leverage the power of automation. But because humans are present, the systems can adapt to novel situations that the automation isn’t set up to handle.



