SREcon Americas 2020: Exposing the Human Factor
How empathy, low context environments, learning from opportunities, and finding common ground can help us work with complex distributed systems at scale


SREcon looked a lot different this year but the breadth of talent and insight on the virtual stage was all the same. Since just last year, I’ve seen an accelerated shift in the focus of top leaders thinking about how to evolve and improve SRE practices.
What I see is a community that wants to expose the human element of a very technical job — how we can make better processes and environments that are harmoniously integrated with machines and technology — to better learn and adapt from incidents and promote continuous improvement.
The conference will be sharing talks on YouTube in a few weeks, and I can’t wait to share some of them. Until then, I want to share a bit on three themes I saw from folks who, like the mission of the conference states, “care deeply about site reliability, systems engineering, and working with complex distributed systems at scale.”
Low Context and Empathy
In her chat, Shubheksha Jalan shared about empathy and getting started in infrastructure. “In tech, we have the tendency to forget where we’ve come from," she said. We forget what it’s like to be a beginner. When onboarding onto a new technology, team, or organization, it’s hard to understand the current patchwork of documentation and processes. They’re often missing important details that are institutional knowledge held by subject matter experts. I call this an “empathy gap” because we’re no longer putting ourselves in the shoes of those who are new and understanding their struggle. It’s like someone saying: “I don’t experience this problem, so it isn’t my problem.”
Tom Limoncelli, SRE Manager at StackOverflow, gave a firsthand account of this “empathy gap” in his talk, “Low Context DevOps: Improving SRE Team Culture through Defaults, Documentation, and Discipline.” He recalled getting started in a new job following a complicated process, including system-specific knowledge and using alternatives to system defaults. In the end, he asked, why wasn’t it all documented since it was a process he wouldn’t have been able to do without assistance? And the reaction was that he should be able to figure it out with all of us many years of Sysadmin experience. Many engineering environments fall into the trap of creating “high context cultures” where it requires people to “read between the lines” to understand what is going on.
I enjoyed Tom’s point of view that we need “low context” environments where “communication is explicit” and “knowledge tends to be codified, public, external, and accessible.” Tom’s top three tips for creating these environments were to:
- Have smart defaults
- Make right easy; the lazy path should fulfill recommended practices and use foundational tools like (CI/CD, Git, etc.)
- Have ubiquitous documentation with a culture of documentation and management’s support
Shubheksha and Tom’s talks built nicely on each other, hitting home that the industry needs better pathways to working on infrastructure, and a smooth path towards that is low-context environments.
Learning From Opportunities Through Questions
The idea of learning from incidents is not new. It’s been a topic now at previous SREcon conferences and elsewhere within the software industry and other adjacent industries. Whether it is during “normal” operations or in an incident, engineers ask themselves and other teammates a lot of questions, like “At what point should we be worried?” “What is normal for this?” “Why does this keep changing?” As an industry, though, I think we sometimes ignore those questions. They either don’t make it into an incident review, or an engineer fears even asking it because maybe they think it’s a silly question.
Talks from Alex Elman, SRE at Indeed, on “Are We Getting Better Yet? Progress Toward Safer Operations” and Cory Watson, Engineer at Stripe, on “Observing from Incidents,” both focused on learning and adapting from past opportunities.
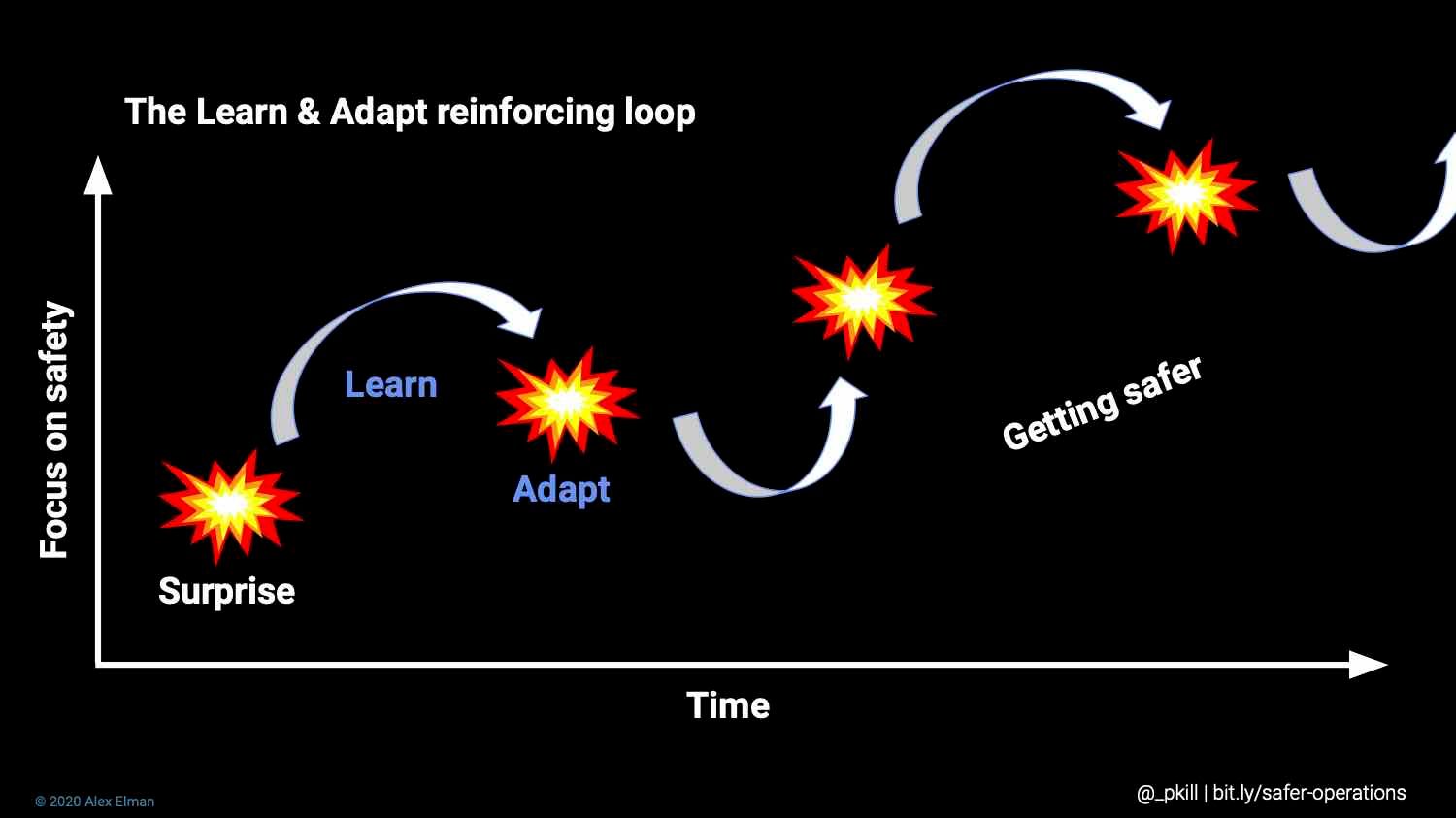
Alex’s talk focused on prioritizing “a learn and adapt safety mode over a prevent and fix safety mode.” It can be hard to know if we are progressing, he said, and we often turn to data for this. I’ve heard this W. Edwards Deming quote many times before: “If you can’t measure it, you can’t manage it.” Alex points out that the quote is actually a bit longer: “It is wrong to suppose that if you can’t measure it, you can’t manage it — a costly myth.” While we need richer metrics, Alex points out that we also need to “be data-driven” while avoiding “being driven by data.”
Other high-level points from Alex’s talk were:
- Deeper understanding leads to better fixes and enduring prevention
- Reliability is reported using SLOs not incidents metrics
- Nobody has control over how an incident unfolds
- Incidents are an opportunity to improve the accuracy of mental models
- At least half of incident analysis should focus on human factors
- Comparative storytelling enhances learning
Cory presented concrete ways to help engineers who do not always benefit from hindsight bias in incidents. Instead of including the exact pattern to spot in an incident in our tools, we should help engineers recognize patterns and instead put this context into our tools. The most basic example of this is putting essential links in a dashboard to relevant SLOs, runbook, feature flags, etc. A more complex example is showing how automation, humans, and the system are working together, instead of having a dashboard for automation and a separate dashboard for the system it is trying to control.
Another example from Cory that we are big fans of at Transposit is the idea of encoding common workflows. If the common questions keep coming up, there should be an easy programmatic way to get those answers.
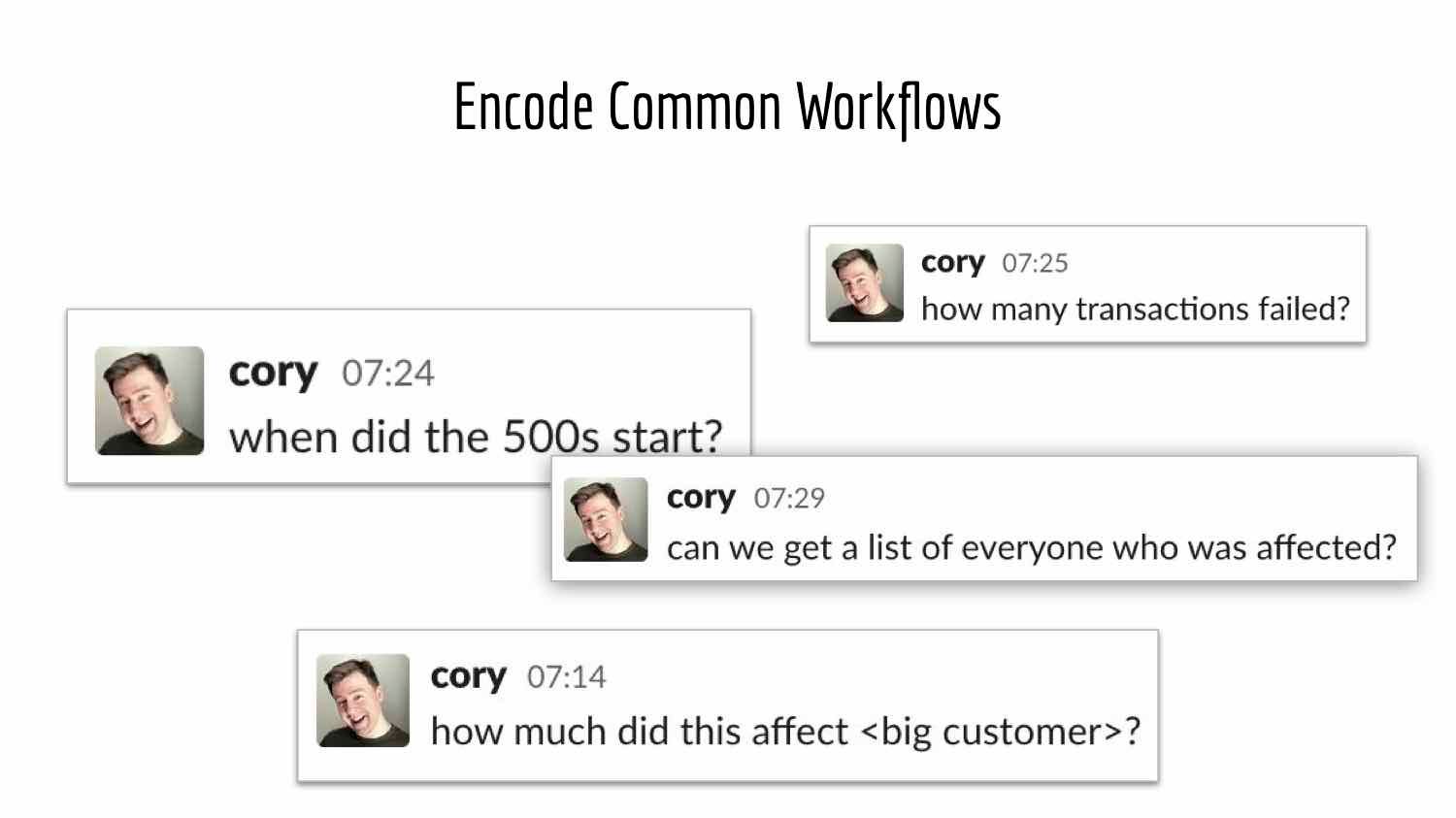
Cory’s talk is full of other concrete examples. I highly recommend checking it out to see how you can bring more context to your team during future incidents while being informed by past experiences.
Incident Command System Disrupted
The last talk I want to touch on was from Dr. Laura Maguire, a researcher at Jeli.io, on “The Secret Lives of SREs - Controlling the Costs of Coordination across Remote Teams.” In her research, she’s found that incident coordination adds a high level of cognitive demand to the human operator.
Dr. Maguire sees that there is a problematic structure of our incident response teams. Often an incident commander has to slow things down, which is the opposite of what our users want in an incident. What if elements of coordination were spread out but run as one system, similar to distributed systems? The reality is, we are often doing this now! Have you ever jumped into an incident and proclaimed in Slack, “I’m checking the logs!” Dr. Maguire’s point of view is that you just disrupted the incident command system by providing “observability into your actions.” I think few would argue against you deciding to check the logs, but how do we get this to work on a larger scale?
For this to work as a larger system, you have to have common ground, which cannot and should not be left to the incident commander. Functional requirements for coordination need to be distributed across the team.
Moving the bar forward
Over the years, SREcon has carved out a special place in the regular conference circuit where conversations like these can happen. It’s an outstanding balance of high level thought and putting it into action with people who deeply care about moving the bar forward. I really enjoyed the emphasis this year on the human factor and how resolving incidents and making on-call life better are not mutually exclusive—in fact, they go hand in hand.
I can’t wait to share some of the talks when they live and update this blog post accordingly. Let me know what your favorite talk was this year and why! I’ll make sure to share. Tweet at me at @taylor_atx.



