Automating away my lunch choices with Transposit
I built an AI to answer the most important question of our times: where should I go to lunch?


Earlier this summer, I decided to apply some artificial intelligence to the one question AI research hasn’t tackled yet: where should I go for lunch?
The challenge
Here at Transposit, we have a lunch poll that’s posted in a Slack channel every day. People in the office vote for where they want to get lunch; it’s a good way to see where your coworkers are headed if you’d like to join them. The polls in this channel date back two years, giving us a fairly long log of daily lunch preferences for every user. As we all know, an AI system is only as good as the data you give it; if I can find a good way to use this data, I just might have a promising lunch AI on my hands.
My first task, as with any data-related problem, was getting all of this lunch poll information into one place. Since we can access Slack conversation history via their API, my journey starts there.
Requesting some data
I needed to grab every relevant lunch poll message from our Slack channel. Since I was requesting so much data, I was initially worried about request pagination. For the blissfully uninitiated: this when an API breaks up the data they’re sending you down into smaller chunks; coupled with complicated auth practices, it can take a lot of time to set up the subsequent requests you need to make to grab each chunk of data. In my personal experience, API pagination and authentication alone have caused a lot of would-be fun projects involving different data sources to never make it past the setup phase.
Luckily, I chose to build my app on Transposit, which handles all of this for me; requesting every single message ever sent to a Slack channel really means just that, even if the relevant channel contains hundreds of messages. So, the first step of this project was really just two operations: finding the ID of our ‘lunch’ slack channel, and then requesting the entire conversation history of that channel, which Transposit returned to me in a nice long JSON array. Since I only wanted the timestamp and “attachments[2].fields” part of each message (where the poll results are stored), I used SQL in Transposit to grab just those components from each element of the conversation history that the Slack API returns:
SELECT ts, attachments[2].fields FROM slack.get_conversations_history
WHERE inclusive=true
AND channel=@channel_id
AND username='Polly'Cleaning that data
Now I have our Slack lunch channel’s entire history laid out before me. This is only the first part of the battle, though: how can I get these messages into a format where I can actually do something interesting with them?
First, I altered the SQL query I that used to get the conversation history to only include messages in the channel that came from the poll bot we use (you can see that in the code snippet above with AND username='Polly'). Then, I wrote some Javascript on top of that query to filter out any options that didn’t receive any votes on a given day. Finally, I used some regular expressions to go through and pull out the options that a given user voted for on each day.
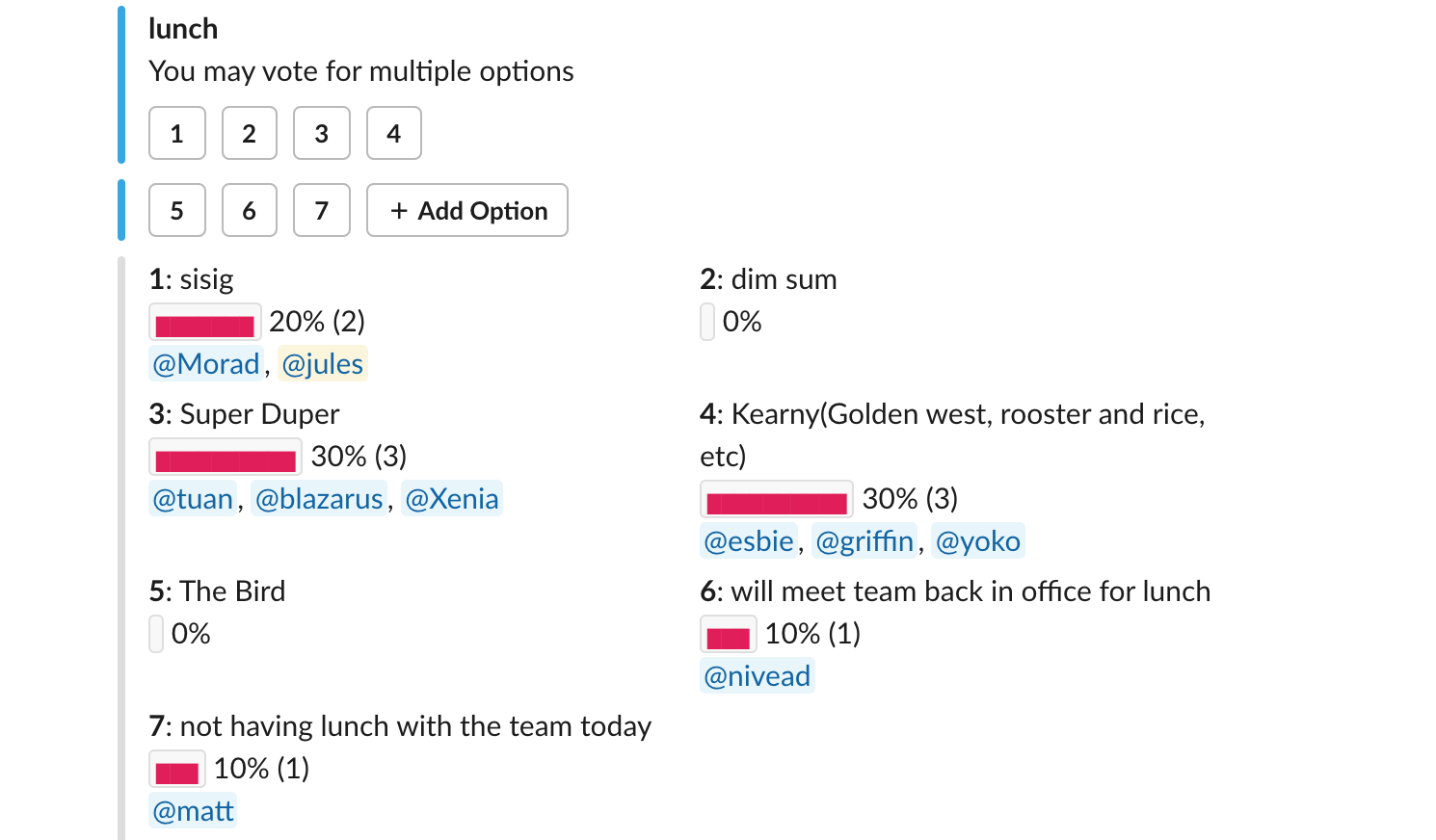
These data cleaning steps helped my conversation log go from this (the black bars are how the poll displays a bar chart of the vote totals):
[
{
"ts": "1563800436.000100",
"data": [
"*1*: sisig\n`▇▇▇▇▇▇▇▇▇▇` 33% (1)\n<@UKWEM4E3H>",
"*6*: will meet team back in office for lunch\n`▇▇▇▇▇▇▇▇▇▇` 33% (1)\n<@UGD7K1F8X>",
"*8*: rooster and rice\n`▇▇▇▇▇▇▇▇▇▇` 33% (1)\n<@UK24Y11S9>"
]
},
{
"ts": "1563541232.002700",
"data": [
"*1*: sisig\n`▇▇▇▇▇▇▇` 14% (2)\n<@UK24Y11S9>, <@UKWEM4E3H>",
"*2*: dim sum\n`▇▇▇▇▇▇▇▇▇▇` 21% (3)\n<@U2615V61Z>, <@U8749R3T9>, <@UK24Y11S9>",
"*4*: Kearny(Golden west, rooster and rice, etc)\n`▇▇▇` 7% (1)\n<@U9YC7F24A>",
"*5*: The Bird\n`▇▇▇▇▇▇▇` 14% (2)\n<@UK24Y11S9>, <@UKWEM4E3H>",
"*7*: not having lunch with the team today\n`▇▇▇▇▇▇▇` 14% (2)\n<@U97NKCFRR>, <@U3A38JXSL>",
"*8*: dosa\n`▇▇▇▇▇▇▇▇▇▇` 21% (3)\n<@UKEKYMRLG>, <@ULA1H9Q7Q>, <@U8749R3T9>",
"*9*: amazon go\n`▇▇▇` 7% (1)\n<@U7YGWP7JQ>"
]
}, …
]To this, for each individual user:
[
{
"ts": "1563800436.000100",
"data": [
"rooster and rice"
]
},
{
"ts": "1563541232.002700",
"data": [
"sisig",
"dim sum",
"the bird"
]
}, ...
]Isn’t that pretty?
Doing fun things with the data
Now I have, for any given user, a complete history of the lunch options they chose on each day. How might I then use this data to then predict where they’d want to go to lunch? Instead of throwing this time series data into a black-box machine learning algorithm, which I normally might do, I first thought of what sorts of factors affect my own daily lunch decision. Immediately, an easy one stuck out: what I did for lunch the day before. For example: a common response to “why don’t you want to go to Bini’s?” is “because I went there yesterday” (unless you, like my co-worker Matt, go to Bini’s every day, in which case you don’t need this bot in the first place). From this simple observation, a basic algorithm emerged: our lunchbot will first find where you went to lunch yesterday. Then, it will look at every time you went to that place in the past, tally up the places you went to on the following day, and return the most common restaurant from that tally. To those that would argue this calculation isn’t complicated enough to warrant the label “artificial intelligence”: the most effective checkers AI is just a big lookup table. Checkmate.
To implement my idea, I wrote another JavaScript operation that steps through the poll history I compiled above, and builds up a mapping of lunch choices to counts of where the user went the following day. One factor that makes this a bit more interesting is the fact that someone can select multiple choices on the lunch poll on a given day: in this case, I just add a tally for each choice the user picked.
var counts = user_history.reduce(
(restaurant_mapping, current_restaurants, index) => {
let previous_restaurants = user_history[index + 1];
// if there's a previous entry in the history
if (previous_restaurants) {
// go through each previous restaurant
previous_restaurants.data.forEach(previous_restaurant => {
// if it's already in our mapping, +1 to the current
// restaurant
if (previous_restaurant in restaurant_mapping) {
current_restaurants.data.forEach(current_restaurant => {
if (current_restaurant in restaurant_mapping[previous_restaurant]) {
restaurant_mapping[previous_restaurant][current_restaurant]++;
} else {
restaurant_mapping[previous_restaurant][current_restaurant] = 1;
}
});
// otherwise, just make it contain 1 for each of
// the current restaurants
} else {
restaurant_mapping[
previous_restaurant
] = current_restaurants.data.reduce((a, b) => {
a[b] = 1;
return a;
}, {});
}
});
}
return restaurant_mapping;
},
{}
);Deploying my app
Now that my app was able to take in a user ID and spit out an informed recommendation, I now wanted a way to a) easily summon Lunchbot for a recommendation and b) let the rest of my coworkers get recommendations themselves (some of them have been here for the full 2 years the poll has existed, so we’d have even more data to inform our calculation). Again, since I was building my app on Transposit, I didn’t have to do much to accomplish this.
I went to my Slack API page and created a new app for our workspace, and added a slash command to this app (‘/lunch’). Then, I went back to Transposit and created a new ‘Webhook’ operation. I grabbed the webhook URL from this operation and updated my slash command so that every time a user used ‘/lunch’, it would call this new operation in my Transposit app. Finally, I added some simple code to the body of that Webhook operation that would call my recommendation function with the user ID of the user who summoned lunchbot, and post a message back to the user with its recommendation.
And that was it! I posted a link to log in to the app to our lunch channel, and within a few minutes my coworkers were discussing their Lunchbot-imposed culinary fates.
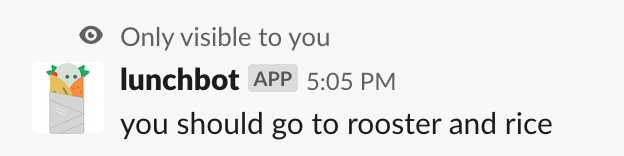
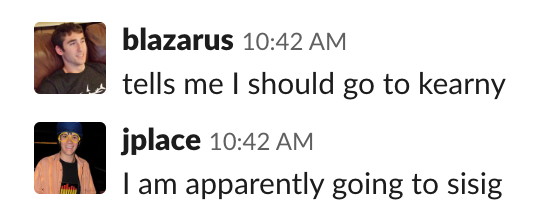
This first round of lunch recommendations revealed a few things I’d like to change in my algorithm. For instance, it’d be nice to return something better than “sorry, I can’t help you” if yesterday was the first time the user went to a particular restaurant. This is where the ease of deployment in Transposit becomes doubly helpful, because there are some things you just won’t encounter until people start actually using your application.
I was shocked that - maybe for the first time in my life - the majority of the time that I spent building a data-driven app was actually spent doing fun stuff with the data. I still have interesting application design problems to think about, but they’re actually interesting things that I want to be thinking about. Transposit does abstract away the tedium, but it also leaves you with full control over the non-tedium.
Final questions
Now that Lunchbot has been given lunch decision control for some real humans, we’d be committing a serious ethical oversight if we didn’t discuss the ethical implications of such a powerful nascent AI. If Lunchbot tells my coworker Yoko to go to Tropisueño for lunch, and her carne asada burrito isn’t up to par, who’s to blame? Is it me, for building the app? Is it Yoko, for deferring to its decision-making powers? I think there’s a third option here now, one that I’d initially overlooked. Without Transposit, I wouldn’t have been able to create Lunchbot, nor would Yoko have been able to summon it to deliver that ill-fated recommendation. Could Transposit be the real culprit here? Fork the Lunchbot app and decide for yourself!



