Getting Started with AWS Athena
Use Transposit to build an app that makes it easy to transform logs into a format Athena can understand, and reduce the time to set up Athena from hours to minutes.


AWS is constantly introducing new tools that lots of people want to experiment with, but you have to get elbow-deep in AWS docs to set it up and take lots of time to figure out how to use the new product, often with limited documentation and examples. In a case like Athena, a serverless interactive query service provided by AWS, the problem is further exacerbated by the fact that you need your data in the right format and location. I came across this blogpost when researching how to set up a good workflow to use Athena to analyze my Cloudwatch logs. In this post, I will use Transposit to build an app that makes it easy to transform logs into a format Athena can understand, and reduce the time to set up Athena from hours to minutes.
How to set up Athena – the usual way
Let’s first take a look at what developers need to do to try out Athena. This blogpost explains how people usually set up Athena to query Cloudwatch logs and the various pain points along the way. In short you have to do the following:
- Export a log group to an S3 bucket in the UI
- Transform the logs into the right format for Athena. You have to write a script that runs locally to process all of the logs
- Upload the processed logs back to a S3 bucket for Athena to query
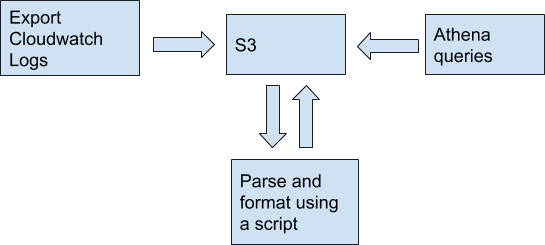
This is an intuitive flow, but has some shortcomings:
- 1. As the author himself noted: “Downloading data to process it locally and re-uploading it feels a bit old fashioned (because it is!)”!
- 2. You have to manually click on “Export Cloudwatch Logs” button in AWS for every log group. This is going to be pretty painful if you have many log groups.
- 3. This process makes it impossible to query your logs in real time.
An obvious improvement to this flow would be replacing the step to run a script locally to using a Lambda function. A Lambda function can be put on the receiving end of log streams and process logs in almost real time. A major pain point is that if your logs do not conform to one of their standard formats, customization is painful.
Why is customization so hard? The Lambda template expects you to put in a big regex for your log format, which can take a long time to write and test.
A step-by-step guide to use Athena with Transposit
If you’re looking to play with Athena, Transposit is a great way to get started. This step-by-step guide shows you how to utilize Athena in your infrastructure. The workflow we are trying to set up is as follows:
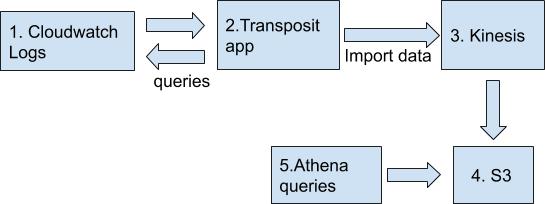
Step 1: Create a Kinesis Firehose Stream to import data to a S3 bucket
For a firehose to put data in your S3 bucket, it needs the right set of permissions to do so. In this step we will create a firehose and grant all necessary permissions.
Navigate to Kinesis Firehose in your AWS console and click on “create new firehose”, with the following settings:
Source: Direct PUT or other sources
Transform source records with AWS Lambda: disabled
Convert record format: disabled
Destination: Amazon S3, choose a bucket and click on ‘Next’Then set S3 buffer and its compression/encryption. You should modify the buffer size/buffer interval per your own preferences.
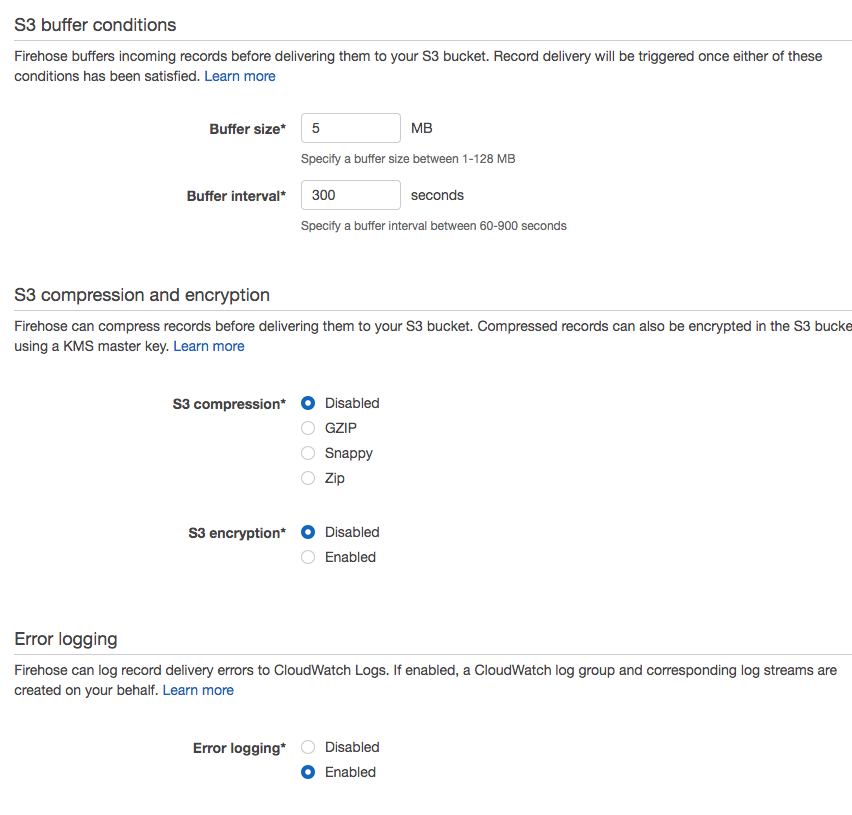
Lastly, create a role and attach it to this delivery stream that you created. Fill in the S3 bucket ARNs and replce [s3_bucket_arn] with your own bucket arns:

{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:ListBucketMultipartUploads",
"s3:ListBucket",
"s3:GetObject",
"s3:GetBucketLocation",
"s3:AbortMultipartUpload"
],
"Resource": [
"[s3_bucket_arn]/*",
"[s3_bucket_arn]"
]
}
]
}Step 2: Set up an AWS user to use Cloudwatch and Kinesis from Transposit
We recommend creating a standalone user that only has programmatic access to AWS for this purpose, so you could disable and delete this set of credentials easily.
With the following permissions:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"firehose:PutRecordBatch",
"logs:FilterLogEvents"
],
"Resource": [insert your log resource arns]}
]
}Step 3: Try running Transposit app!
Navigate to this sample app, fork it, and then click on “Auth & Settings” on the left. Authenticate connectors with the user credential you just created in Step 2. Try running quick_queue_events with parameters, and you will populate your S3 bucket with log events from Cloudwatch!
Note that you may need to update quick_queue_events per your own log format. Generally, you want to extract JSON objects for Athena to index and query.
Step 4: Try Athena (Finally!)
If you have completed the previous three steps, it’s time to finally try out Athena.
As an example: if you have log objects like this: {timestamp: 1565925683, group: 'web', value: 'test'}
You could execute the following command on Athena to create a table named “athena_test” from S3 bucket:
CREATE EXTERNAL TABLE IF NOT EXISTS default.athena_test (
`timestamp` timestamp,
`group` string,
`value` string
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1'
) LOCATION 's3://BUCKET_NAME/FOLDER_NAME/'
TBLPROPERTIES ('has_encrypted_data'='false');To view data processed in this table, select “default” database and run this command from Athena console: SELECT * FROM ATHENA_TEST
What else?
To build on what we have experimented above, you could also try out AWS SQS in this sample app so you can process larger data sets and see live results. The power of Transposit lies in its ability to transform and adapt – start building your own app to harness the benefit of a true serverless platform!



