Remediate Incidents Faster: Take Action & Enhance Visibility from a Single Platform
Human-in-the-loop automated workflows enhance decision-making and actionability, giving humans the power to choose their own path

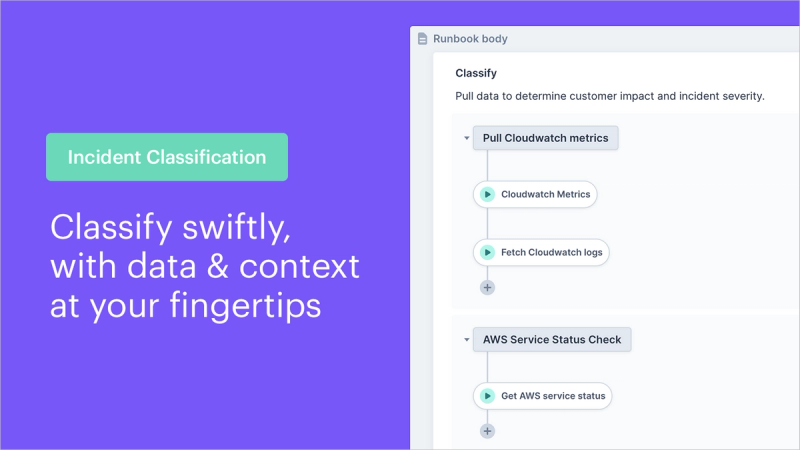
Because of the unexpected nature of incidents, typically no two can be mitigated and remediated in the exact same way. You cannot know how to remediate an incident until you look at data and discern the problem, meaning auto-remediation is often an unfeasible solution. However, you can enable humans to take action faster using human-in-the-loop automation that provides options that guide humans, such as “restart a server,” “scale ECS,” and “rollback a recent deployment.”
In some cases, however, teams can implement auto-remediation, when it is a known and repetitive issue. For example, let’s say a database used by business analysts internally fails periodically due to a known issue that’s yet to be resolved, thus taking it offline. In this situation, an automated runbook could be used to auto-restart the server anytime the database is unresponsive.
While not every incident remediation phase can be fully automated, human-in-the-loop automated runbooks can help make manual tasks easier and faster. The goal is to give humans options and streamline the execution of their decisions.
By the time an incident is ready for remediation, it has already gone through the paces of incident intake (creating channels and tickets), pulling metrics and data to classify the incident by severity, and engaging with the appropriate mitigation teams and other stakeholders. Whether it is the incident manager and their team beginning to dig into remediation, or a third party SRE or on-call engineer in the hot seat, it is then up to the teams in charge of remediation to implement their own processes to take care of the problem.

The status quo
Incident remediation today usually means going between various different tools and taking action manually. At the same time, teams and stakeholders lack visibility into what is happening and a comprehensive audit trail to drive continuous improvement and ensure compliance.
Manual toil: Every incident is different, but they will generally require some type of ad hoc manual lift, such as rollbacks, scaling ECS instances, restarting clusters, and other troubleshooting involving CPU, RAM, and other signals and performance indicators. Typically, data pulls and actions must be completed manually across countless tools and platforms. All of this makes the remediation process a slog of repetitive, cross-platform, multi-team tasks and associated clerical duties that bogs down the high stakes of remediating incidents — with money, reputation, sensitive information, or other major issues on the line.
Lack of visibility: Additionally, in situations where the work is being delegated, there is a loss of transparency about progress within the silo of third-party servicing teams. Regardless of the complexity of the issue itself, there are many separate tools and manual tasks that take place in silos and disparate environments, and a lack of efficiency or continuity in how progress is tracked or relayed back to the originator of the task and other concerned stakeholders.
No audit trail: The best practice of documenting steps to remediation and collecting screenshots from within all the different tools and platforms is a major headache. But nonetheless, it must be done manually for posterity, namely audits and reviewing after the fact.
How Transposit solves these problems
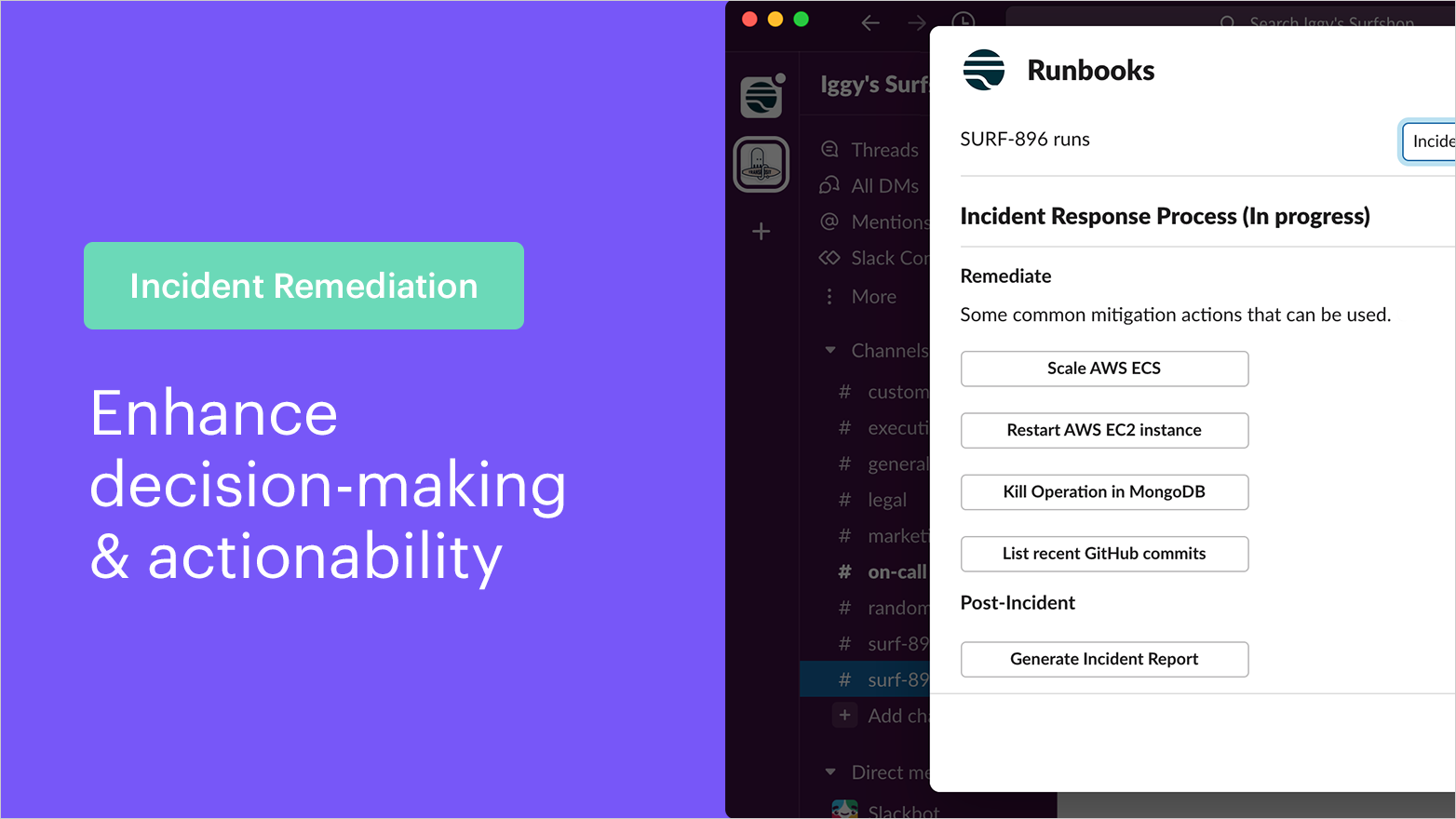
Transposit helps teams take action faster across the stack, surface valuable information, and keep all stakeholders informed. Using automated workflows, teams can use single-click buttons to perform tasks such as rollbacks, scaling, and restarting a server. Beyond the actual remediation steps, Transposit also provides a full audit trail of actions taken, closing the transparency loop, enabling easier retrospectives, and driving continuous improvement. (Note: scroll down in this article to learn how to remediate incidents in Transposit)
Transposit’s human-in-the-loop automated workflows help offer common remediation steps and ensure that every action is recorded within the container of the incident activity. By unifying and streamlining the process, Transposit instantly creates transparency across stakeholders and is able to fully automate some remediations and simplify others to a single click.
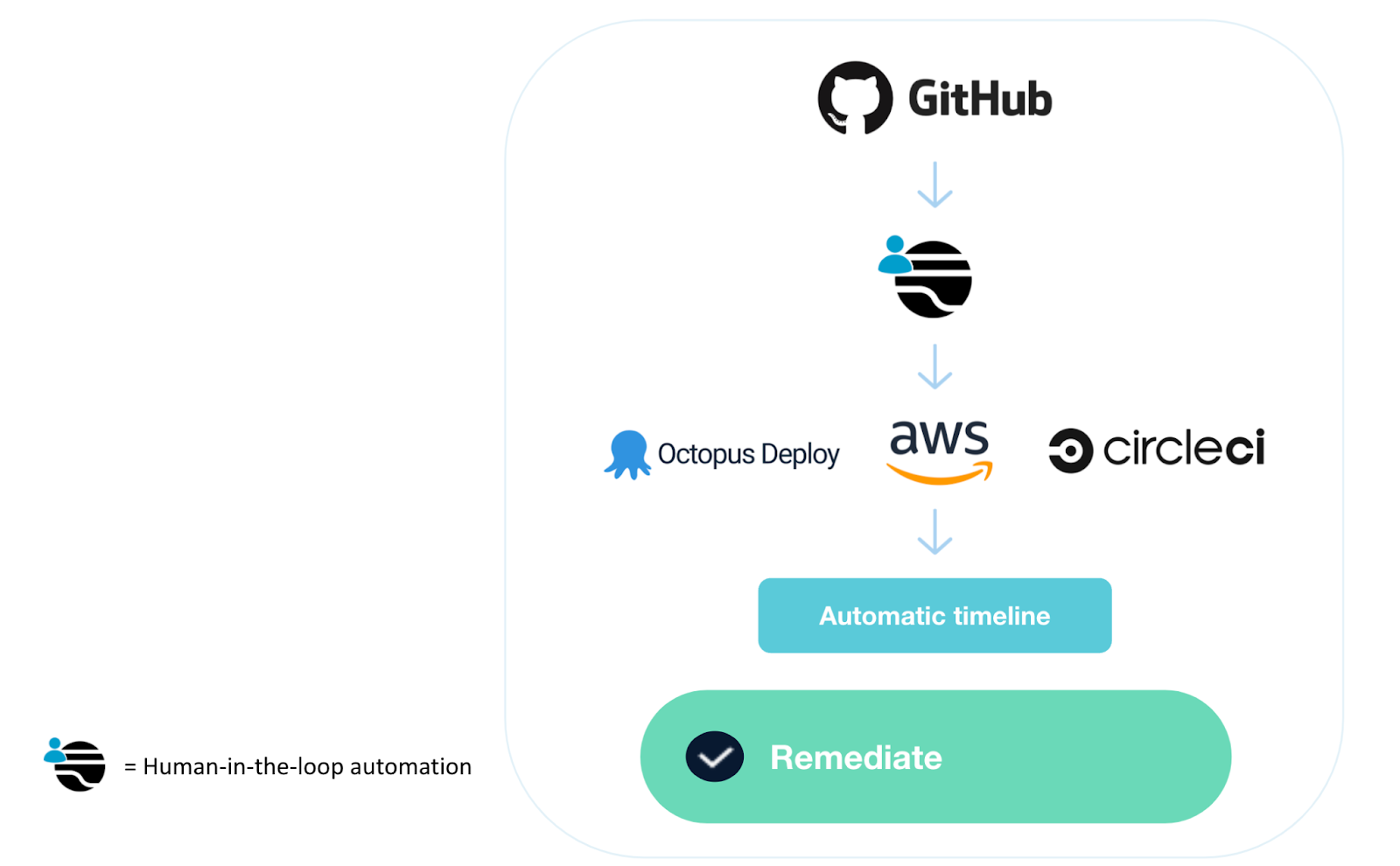
Actionability: Transposit enables humans to take action across the stack from one platform, providing SREs and on-call engineers with prompts and options to rapidly and decisively initiate the next steps with a single click. These prompts can handle tasks dictated by judgment calls, such as pulling recent commits to GitHub, rolling back a change that was made to AWS, restarting a Databricks cluster, or scaling an ECS instance. All of these steps can be initiated straight from Slack (or the Transposit UI).
Visibility: Throughout this process, the statuses of all the actions and activities are visible to all parties through the Transposit dashboard, even those actions that are initiated in Slack. As many tasks take place in disparate platforms and dashboards, such as MongoDB, Octopus Deploy, AWS, GitHub, CircleCi, Databricks, and any of more than 200 programs with pre-built Transposit integrations, the transparency from Transposit cuts through the noise of all of these disparate tasks and teams to make sure that everybody is on the same page.
Automatic audit trail: Transposit automatically documents every action that’s taken (whether in the Transposit UI or through Slack) and harvests the necessary screenshots for a full audit trail, record keeping, and debriefing. This audit trail makes retrospectives easier and ensures teams can improve processes. This record also helps in subsequent incidents, so engineers can look back at how something similar was resolved.
How it works
Transposit is powered by custom-built no-code runbooks that can be set up by any member of your team, with or without coding expertise. With this in mind, different types of runbooks can be tailor-made for all types of incidents, including general tasks that must take place for any incident, or ultra-specific tasks that are only needed for certain types of incidents.
With issues that require absolute responses, such as matters of hitting thresholds of CPU usage or RAM or other situations that may be triggered by metrics or signals, runbooks can be set to address these instantly without requiring human oversight.
But when there is a circumstance that sits at the top of a decision tree waiting on a judgment call from a human, runbooks can be set to present the incident commander, on-call service provider, or third-party team with options that cue a series of other remediation steps with a click of a button.
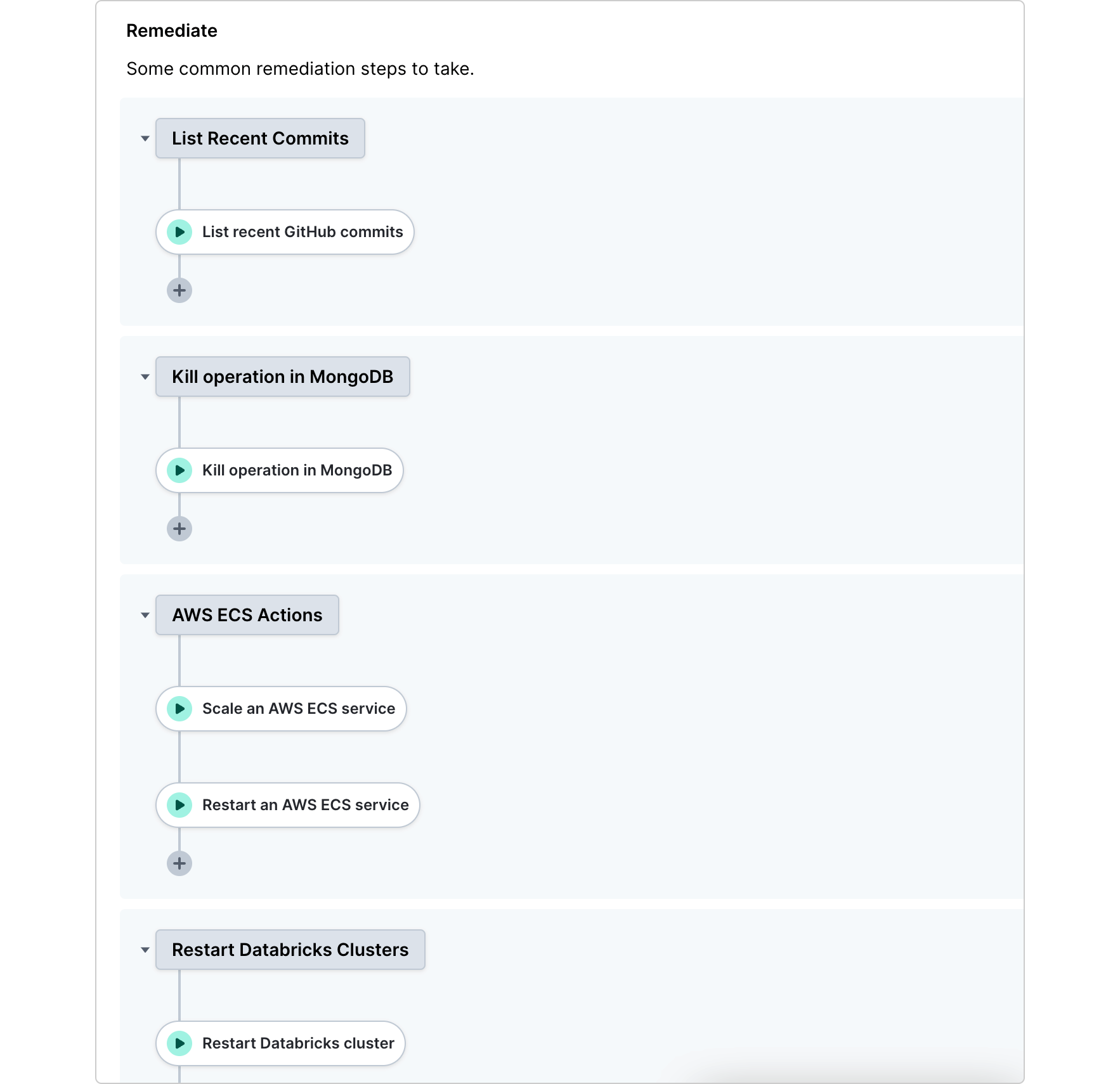
Building your remediation runbook section
- Create a new section for Remediation.
- Add buttons and actions for common remediation steps. See all pre-built actions, or learn how to create new ones.
- Add documentation to the section description to give more context to the operator about when to use any given action.
Once built, you can run the entire workflow from within Slack. Just use the command /Transposit to pull up the current runbook being used and choose an action to take.
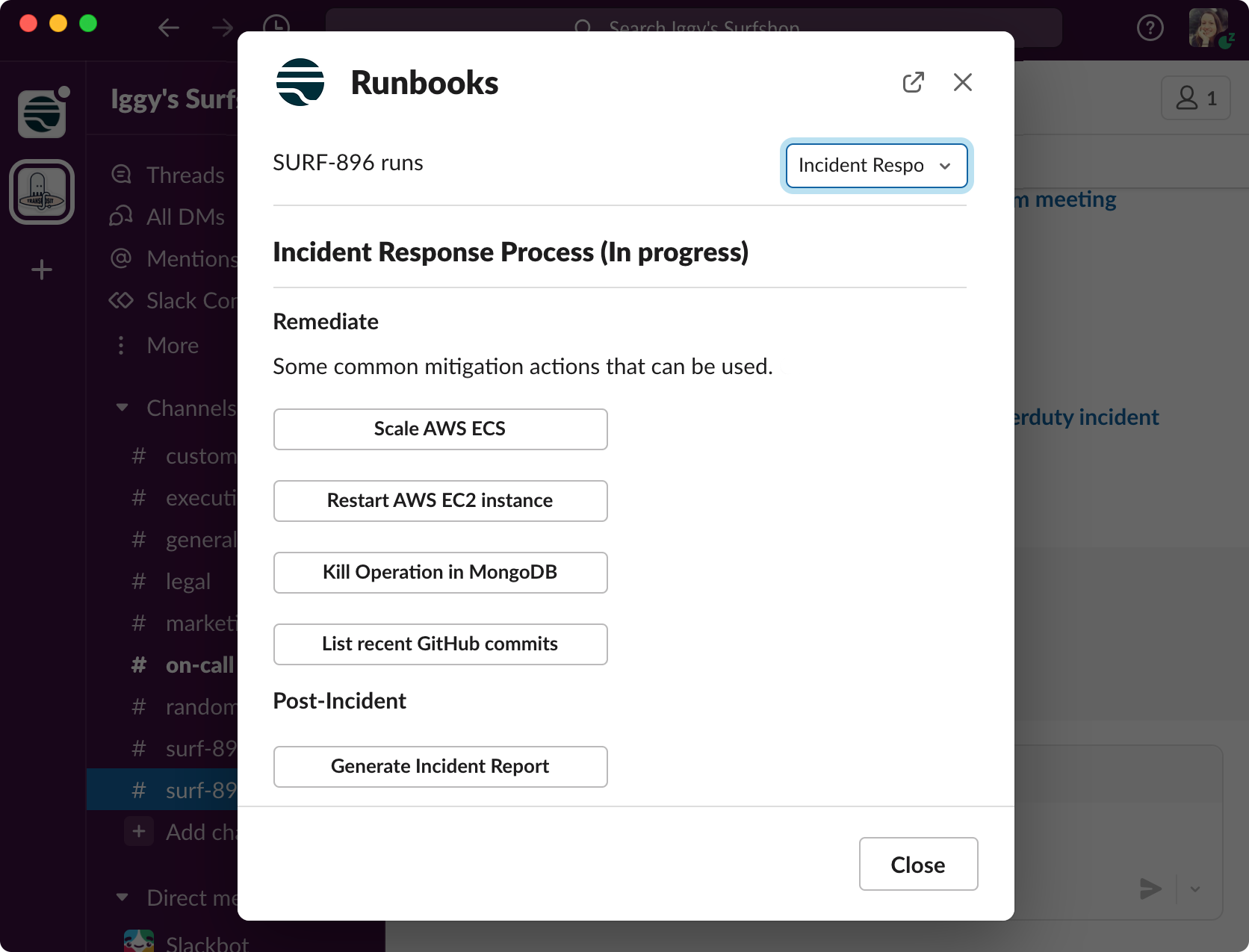
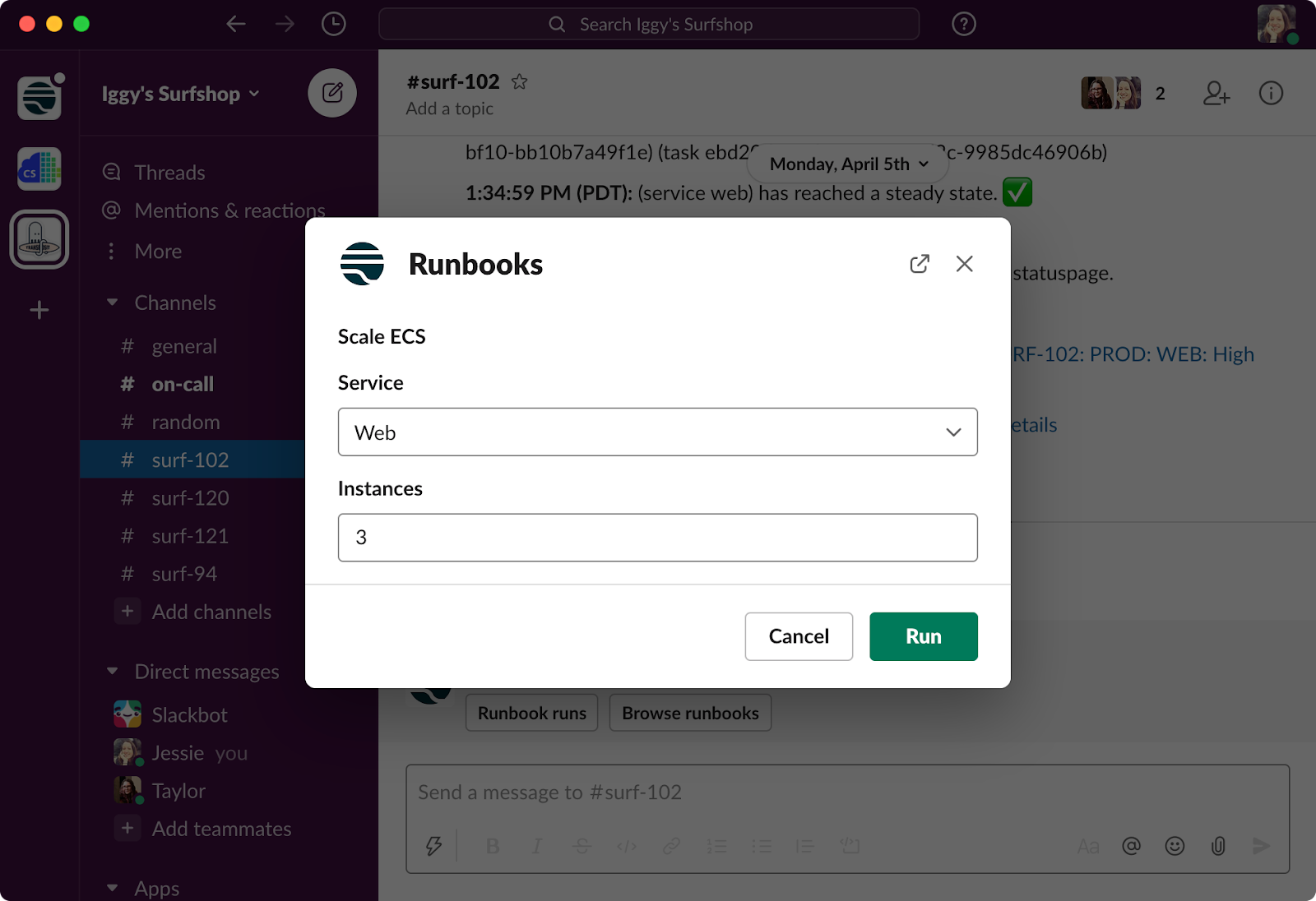
Every action taken in Slack or Transposit will be automatically recorded in the incident timeline. Easily export a post-incident report using the “Generate Confluence Postmortem” or “Generate Google Docs Postmortem” actions.
What’s next
Once the incident has successfully gone through remediation, Transposit is ready to help troubleshoot and future-proof the remediation process of future incidents with Report, Record, and Learn, the final step of the 5-stage approach to incident management.