How to Create a Runbook: A Template for DevOps Teams
A guide to creating and enabling operational efficiency through runbooks and automation


Technical teams rely on specific sets of processes to work efficiently. Examples can range from provisioning equipment and onboarding a new hire to responding to an urgent outage and/or incident impacting customers.
One of the best ways to guarantee that TechOps runs like a well-oiled machine is to use runbooks. A runbook should include a precise and concise set of instructions for solving a technical challenge or performing an operational task. Providing these steps in runbooks can help:
- ensure work consistency
- reduce human error
- reduce knowledge silos and gaps
- enable more people to add value (especially newer teammates)
- allow teams to quickly perform routine tasks
Streamlined processes ultimately provide value to both the business and customers by ensuring services remain available and the increased efficiency allows for free time to work on adding new features or other important tasks.
No matter which function or team your runbooks seek to support, organizations should prepare runbooks in a manner that prioritizes the availability of the most valuable and actionable information, minimizing time wasted. Runbooks for incident response, for example, should include information about how to intake alerts and events and classify and investigate the incident, as well as common remediation steps, contacts for service teams, and escalation procedures. While there is a significant focus on using runbooks for incident management, they should function as a vital part of technical operations at large.
Let’s explore how to create a quality runbook.
Guidelines for creating a high-quality runbook
Composing documentation or a high-quality runbook isn’t always easy. We’ve written previously about what makes a good runbook: that it is actionable, accessible, accurate, authoritative, and adaptable.
At their core, the ‘five A’s’ ensure:
- A runbook follows a standard format. Think of it as a template. While not a strict requirement, it is preferable that all IT team units use a standardized runbook format. This consistency makes it easier for someone to jump in and get to work right away, even if it is another team helping out during an incident.
- There is a single runbook for each task, incident type, and specific events like requests and deployments.
- A runbook has clear, step-by-step instructions, enabling anyone to understand the core concepts of the system or application, regardless of their level of familiarity.
- The runbook steps integrate testing.
- Incident management runbooks explain the correct escalation path, decision-making flow, and contact details of the escalation team and key stakeholders.
- The company organizes regular runbook review processes to guarantee consistency and accuracy of the runbook’s content.
Runbooks versus playbooks
Before demonstrating how to create a runbook template, let’s compare runbooks with playbooks, as organizations often use the two in combination (although some organizations do use the terms interchangeably).
A playbook tends to include multiple runbooks. Playbooks also typically contain more supplemental knowledge about responsibilities, contact information, parameters, and general instructions (such as the access key to the server room). In contrast, runbooks cover a single task, whether simple or complex.
For example, a playbook describes all operations during a maintenance window. Its various runbooks detail how to shut down system X, restart application Y, and validate workload Z after maintenance.
Creating a runbook template
So how do we use these attributes of a ‘good runbook’ in practice? Note that you can make the strategy available through whichever method your organization relies on for documentation: Microsoft Word, Google Docs, Confluence, or a company wiki.
The scenario we will use is a server with a spiking CPU blocking applications from running healthily. For this example, we will keep the details generic and not target a specific platform.
Based on the information outlined earlier, we should start by identifying the core data fields to capture for each step. A sample list might appear as follows:
- Task ID
- Task name
- Task description
- Task details
- Team executing this task
- Task owner
- Time duration to complete the task
- Status
This results in the following runbook table:
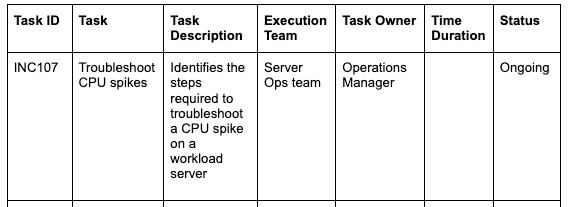
- INC107 is the unique task ID listed in your IT service management (ITSM) tool or database.
- The task is well-defined and has clear boundaries.
- The task description provides a more detailed overview of what the task involves.
- Execution Team and Task Owner indicate execution responsibilities.
- Time duration could be a relevant parameter for the escalation task, indicating how much time we should spend troubleshooting (which is the core of this task) before escalating the job.
- Status might be scheduled, ongoing, closed, escalated, or even more granular.
On a lower level, this runbook has sub-tasks:
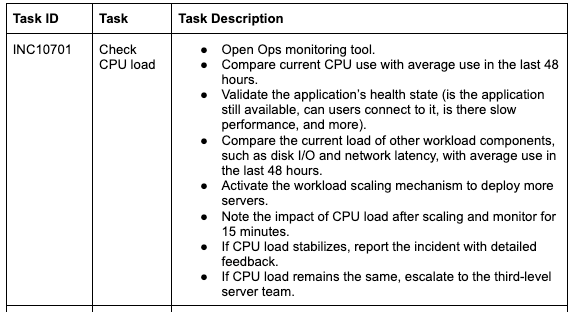
In this scenario, the engineer troubleshooting the incident should be clear about what to do and how to do it. Also, the runbook identifies specific parameters (the “if” statements) to validate successful actions or escalate when necessary.
While still concise, the runbook should give your Ops team a good idea of what is possible when switching from standard documentation guidelines to actionable runbooks.
Automating runbooks
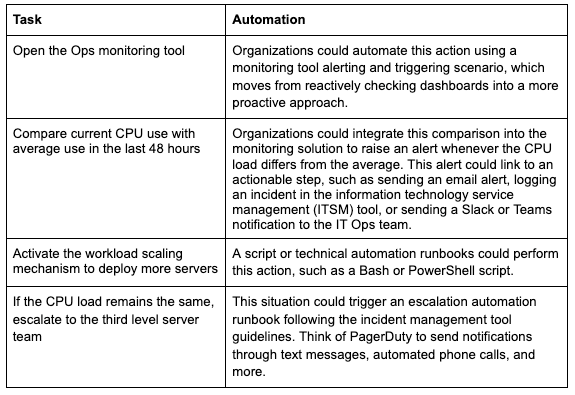
While these “manual” methods of creating runbooks do work, there are more streamlined and effective ways to develop and manage runbooks. Notice that organizations could almost entirely automate nearly every step in the previous example. Let’s reuse some of the task steps and consider this automation.
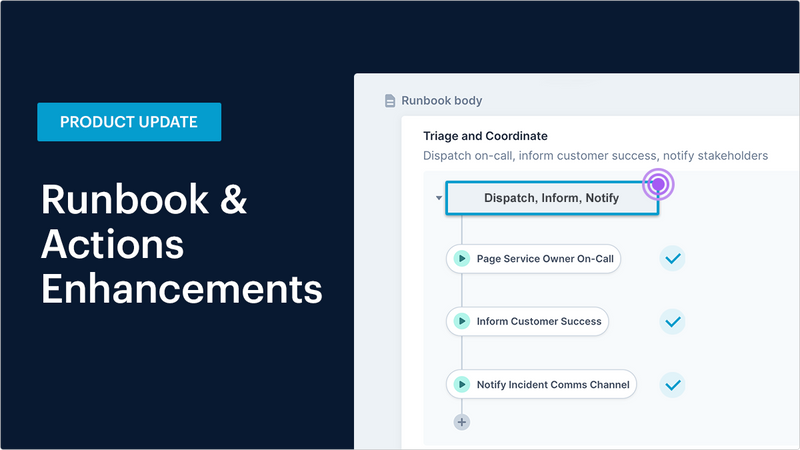
Human-in-the-loop automated runbooks
There is nothing wrong with building this automated sequence of tasks using in-house DIY methods. However, a more streamlined solution like the one provided by Transposit is a quicker and more effective means of adding automation capabilities.
Through a collection of hundreds of connectors to several standard external services, as well as any in-house tooling, Transposit makes the automation process straightforward and complete. Our getting started guide shows how easy the process can be.
Another pain point in incident management is maintaining relevant and up-to-date documentation. From inventory to step-by-step instructions for the engineers, and a summary of the post-incident reviews, there can often be too much information to allow for proper tracking. In addition to transforming the manual steps from your runbook task list, Transposit helps produce dynamic documentation that can be updated on the fly, guaranteeing its accuracy and relevance. To learn more about why this capability is so essential and its purpose, check out Forbes’ Why Dynamic Documentation Should Be At The Heart Of DevOps.
Runbooks help your team members remain focused and consistent when taking care of routine tasks or responding to an incident. Including automation within runbooks helps save time and enables team members to focus on other areas of importance. Connect with us to learn more about how Transposit’s human-in-the-loop automated runbooks can streamline your incident management or other operational tasks.